
Angular框架解读--Ivy编译器的视图数据和依赖解析
更新日期:
作为“为大型前端项目”而设计的前端框架,Angular 其实有许多值得参考和学习的设计,本系列主要用于研究这些设计和功能的实现原理。本文主要介绍在 Angular 的 Ivy 编译器中,是如何管理和查找视图数据的。
Ivy 模型
在上一节《Ivy 编译器整体设计》中,我们从整体上介绍了 Ivy 编译器主要做的一些事情,包括模板编译、TypeScript 解析器等。我们可以看到 Ivy 编译器实现了更优的 Tree-shaking 支持、组件的延迟加载、支持增量编译等,而达到这些效果的一个核心设计点便在于视图的解析和数据管理。
视图数据 LView/TView
在 Angular Ivy 中,使用了LView和TView.data来管理和跟踪渲染模板所需要的内部数据。
其中,LView存储了从模板调用指令时,处理指令所需的所有信息。每个嵌入式视图和组件视图都有自己的LView,我们来看看LView的定义:
1 | export interface LView extends Array<any> { |
我们能看到,LView中存储了足够多的信息,这样的设计使单个数组可以以紧凑的形式包含模板渲染所需的所有必要数据。
其中,[TVIEW]为该视图的静态数据,存储了所有可在模板实例之间共享的信息(比如template、components、data以及各种钩子),以便可以轻松地在 DI 中遍历节点树并获取与节点(存储指令defs的节点)关联的TView.data数组。这些信息存储在ComponentDef.tView中。
显然,LView还存储了除此之外的所有渲染模板需要的信息,比如:
[PARENT]用于存储父视图。在处理特定视图时,Ivy 将viewData设置为该LView;完成该视图的处理后,将viewData设置回原始viewData之前的状态(父LView)[NEXT]用来链接组件视图和跨容器的视图[T_HOST]存储当前LView插入位置的TNode,因为“子级”除了插入到“父级”中,还可以插入到任何地方,因此不能将插入信息存储在TView中[DECLARATION_VIEW]用于存储“声明视图”(声明模板的视图),因为动态创建的视图的模板可以在与插入的视图不同的视图中声明,因此,上下文应继承自声明视图树,而不是插入视图树[CHILD_HEAD]存储引用层次结构中此LView下的第一个LView或LContainer,以便视图可以遍历其嵌套视图以除去侦听器并调用onDestroy回调[CHILD_TAIL]存储层次结构中此LView下的最后一个LView或LContainer,尾部使 Ivy 可以快速向视图列表的末尾添加新状态,而不必从第一个孩子开始传播
LView的设计,可以为每个视图保留单独的状态以方便视图的插入/删除,因此我们不必根据存在的视图来编辑数据数组。
LView/TView.data 数据视图
在 Ivy 中,LView和TView.data都是数组,它们的索引指向相同的项目。它们的数据视图布局如下:
| Section | LView |
TView.data |
|---|---|---|
HEADER |
上下文数据 | 大多数为null |
DECLS |
DOM、pipe 和本地引用实例 | |
VARS |
绑定值 | 属性名称 |
EXPANDO |
host bindings; directive instances; providers; dynamic nodes | host prop names; directive tokens; provider tokens; null |
其中:
HEADER是一个固定的数组大小,其中包含有关模板的上下文信息。主要是诸如父级LView`Sanitizer、TView`之类的信息,以及模板渲染所需的更多信息DECKS包含 DOM 元素、管道实例和本地引用,DECKS节的大小在组件定义的属性decl中声明VARS包含有关如何处理绑定的信息,VARS部分的大小在组件定义的属性var中声明EXPANDO包含有关在编译时未知大小的数据的信息。比如Component/Directives,因为 Ivy 在编译时不知道会匹配哪些指令
至于具体的例子这里便不展开介绍了,你可以从 DOCS: View Data Explanation 文档中找到。
Ivy 中 的 DI
在 Angular DI 中,注入器获取对应的示例依赖于 token 令牌。Ivy 将所有令牌存储在TView.data中,将实例存储在LView中,因此我们可以检索查看该视图的所有注入器。
而 DI 查找依赖的过程,离不开NodeInjector。
NodeInjector
上一节中,我们介绍了 Ivy 编译器中使用增量编译来优化构建速度,增量编译意味着一个库只会根据变更的部分进行重新编译。要做到增量编译,Ivy 编译器不得依赖未直接传递给它的任何输入(可理解为“纯函数”)。使用Lview来存储每个视图的状态和数据,则可以通过 DI 注入依赖的视图数据。
在《Angular 框架解读–多级依赖注入设计》一文中,我们介绍了 Angular 中的两种注入器:模块注入器ModuleInjector和元素注入器ElementInjector。Angular 通过依次遍历元素注入器树和模块注入器树来查找提供令牌的注入器。
实际上,在 Ivy 中使用NodeInjector替换了 View Engine 中的元素注入器:
1 | export class NodeInjector implements Injector { |
其中,getOrCreateInjectable方法从NodeInjectors到ModuleInjector进行遍历,并返回(或创建)与给定令牌关联的值。
DI 查找依赖的过程
我们知道 Angular 会构建一棵视图树,该视图树总是以只含一个根元素的伪根视图开始(参考《Angular 框架解读–视图抽象定义》)。
Ivy 使用LView和TView.data数组来存储视图数据,其中便包括了节点的注入信息。这意味着,NodeInjector需要从LView和TView.data数组中得到具体的视图数据信息。
我们可以从getOrCreateInjectable中看到该过程:
1 | export function getOrCreateInjectable<T>( |
从上述代码中,如果我们调用injector.get(SomeClass)方法,会产生以下步骤:
- Angular 在
SomeClass.__NG_ELEMENT_ID__静态属性中查找哈希。 - 如果该哈希是工厂函数,则还有另一种特殊情况,即应通过调用该函数来初始化对象。
- 如果该哈希等于-1,则是一种特殊情况,我们将获得
NodeInjector实例。 - 如果该哈希是一个数字,那么我们会从
TNode获取injectorIndex。 - 查看模板布隆过滤器(
TView.data [injectorIndex]),如果为真,那么我们将搜索SomeClass令牌(通过tNode.providerIndexes可以找到所需的令牌)。 - 如果模板布隆过滤器返回错误,那么会查看一下累积布隆过滤器。如果它为真,则继续进行遍历,否则将切换到
ModuleInjector。
该过程可以用以下流程图表示:
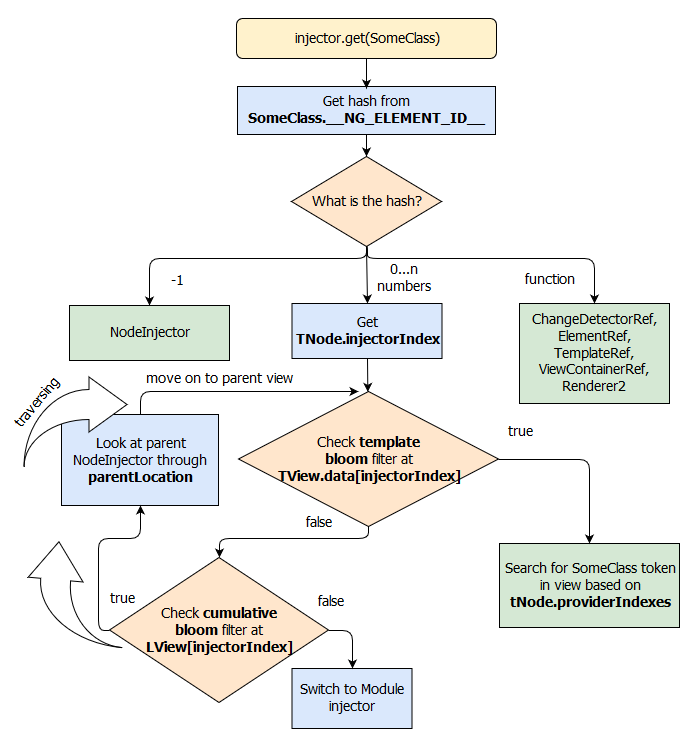
这便是在 Ivy 中,使用NodeInjector来解析依赖关系的过程。可以看到,该过程中还使用了两个布隆过滤器:累积布隆过滤器(cumulativeBloom)和模板布隆过滤器(templateBloom)。
布隆过滤器
布隆过滤器常用于加快数据检索的过程,属于哈希函数的一种,你可以阅读 Probabilistic Data structures: Bloom filter 一文来了解它。
在 Ivy 中,一个视图可以具有与为该视图上的节点创建的注入器数量一样多的布隆过滤器。下图为可视化结果:
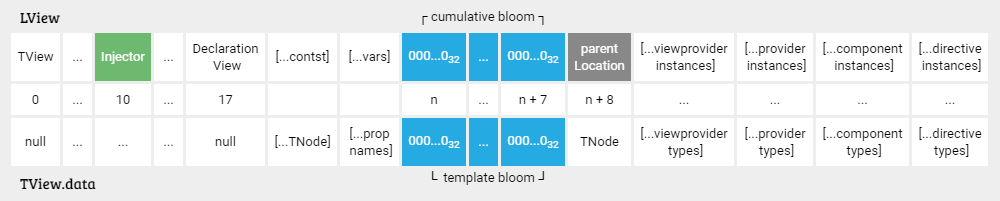
可以看到,布隆过滤器存储在前面提到的LView/TView.data布局中的EXPANDO部分:
LView和TView.data数组可以包含许多布隆过滤器,长度为 8 个时隙([n,n + 7]索引),它们的数量与为其创建喷射器的节点数量成正比- 每个布隆过滤器在“压缩的”
parentLocation插槽(n + 8 索引)中都有一个指向父布隆过滤器的指针
我们结合NodeInjector中查找依赖的过程,以以下简单的代码为例:
1 | ({ |
在 Ivy 中,上述代码会生成这样的可视化视图:

Ivy 在TNode上创建了InjectorIndex属性,以便知道专用于此节点布隆过滤器的位置。除此之外,Ivy 还在LView数组中存储了parentLocation指针,以便我们可以遍历所有父注入器。
而我们也看到,NodeInjector是具有对TNode和LView对象的引用的对象。因此,每个NodeInjector分别保存在LView的 9 个连续插槽和TView.data的 9 个连续插槽中,如图:

那么,上面简单的代码示例中,DI 查找依赖的过程如图:
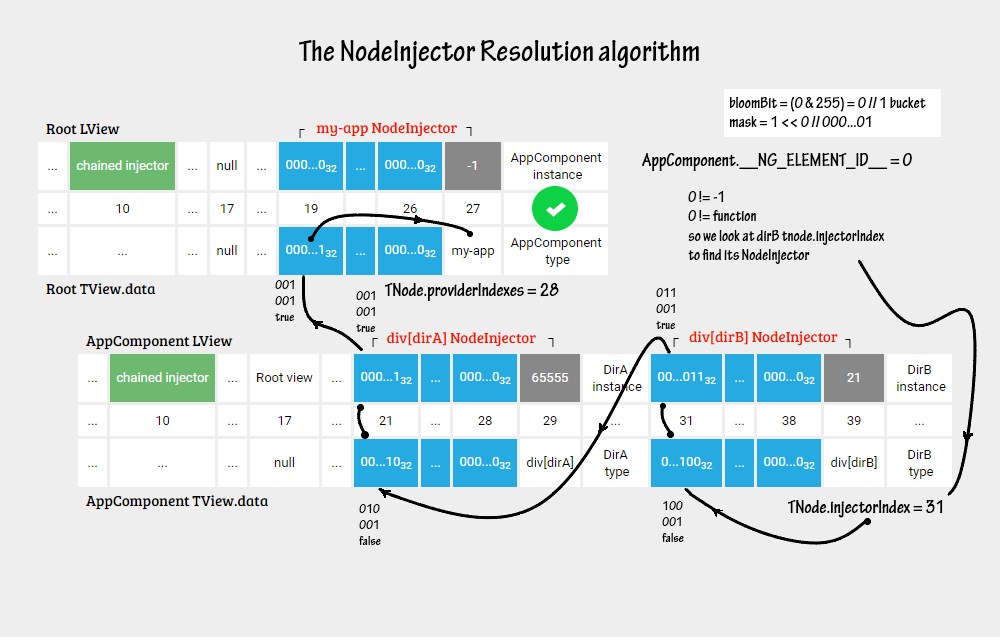
总结
今天给大家介绍了 Ivy 编译器中的数据视图LView/TView,而依赖解析过程中需要从中取出对应的数据,该过程使用到NodeInjector。NodeInjector用于创建注入器,为了加快 DI 搜索依赖的过程,Ivy 还设计了累加布隆过滤器和模板布隆过滤器。
这些内容,是理解 Angular 中依赖注入过程中不可或缺的。而在查阅这部分文章和代码之前,我甚至无法想象在 Angular 中依赖注入过程如此复杂。很多时候,我们都认为前端领域并不存在太多的算法和数据结构相关的内容,实际上可能只是我们并没有接触到而已。
参考

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢