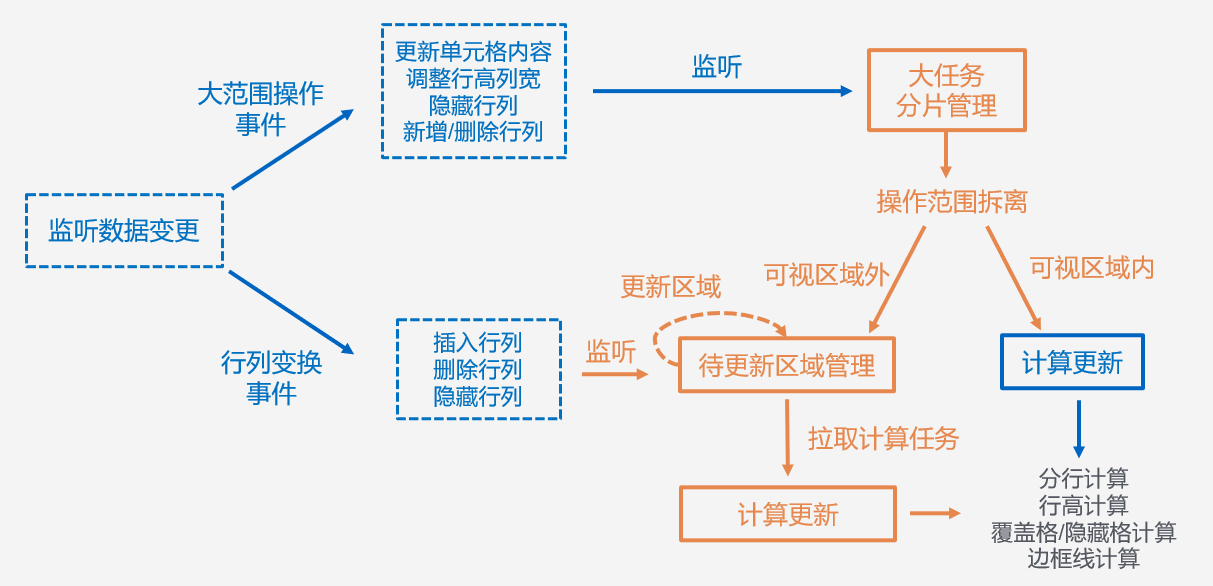
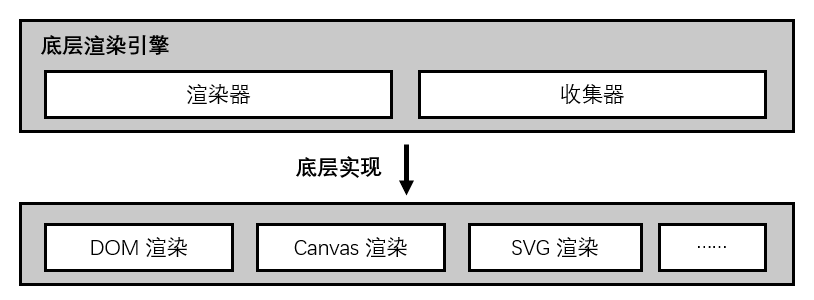
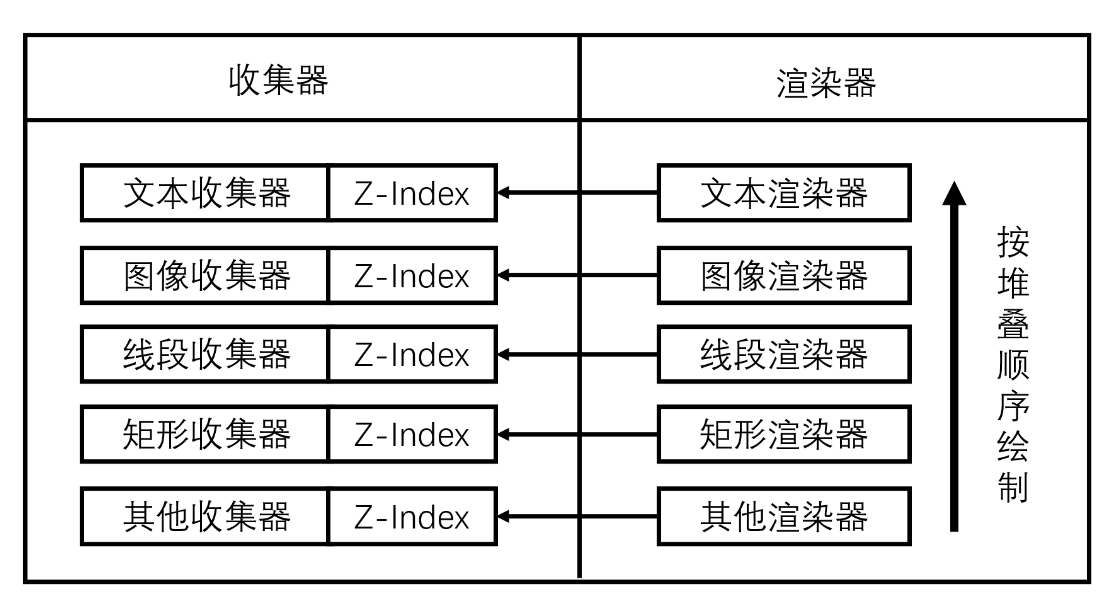
我们还没离开校园的时候,就已经知道要对自己未来的职业发展进行规划。但并没有人会来教会我们这些,而我们在一股脑扎进工作里以后,又常常因为忙也好因为懒也好,觉得目前状态还可以,就把职业规划也扔脑后了。当我们想起来要考虑下自己未来工作方向的时候,常常是因为遇到了瓶颈。大多数人都是在遇到工作困境的时候,才会开始思考要怎么度过难关。但其实做工作规划最好的时候,就是在问题出现以前。
找准自身定位
想要对自己的未来制定一些方案,得知道自己要去哪里。在团队里,可以根据自身喜好和团队的方向来找到自己在团队中的位置。但职业规划和团队中的定位不一样,首先我们要确定自己未来的发展方向。
未来发展方向
对于程序员来说,未来的发展方向无非就几个:深挖技术领域、转型技术管理、转型其他类型管理、转行、考公务员等等。在前端领域,可以分为纯前端、全栈等方向,而纯前端和全栈也都各自有更加细分的领域,比如性能、渲染、动画绘制等等。
至于具体要选哪个方向,大都由个人偏好决定。一个人想要做什么事情,会同时受到很多因素的影响,除了自己对技术的热情和能力,还可能包括遇到的一些人和事,例如特别崇拜的某个开发、尊重的某位前辈、遇到过一些不公正的事情、或深感触动的一些事情,都可能会成为我们想要立志做某件事的契机。
很多时候,即使我们已经确认想要去往哪个方向,但实际上依然会被未来的某些事物改变。正如很多公司要求员工写 KPI,员工将 KPI 写得再详细,依然在半年后考核时需要重新修改,因为计划永远赶不上变化。但我们不能因为未来可能会变,就认为没有意义,也不去写 KPI。
这就好比我们在做习题本,本子的最后写好了答案,既然都知道自己最后都会看答案,那么我们做不做题、是否做错了都无关紧要了吗?显然不是的,做题是个需要思考计算的过程,通过最终的答案我们可以知道自己的思考方式是否有误、是否需要调整。写 KPI 也是一个道理,我们如果最初定的 KPI 与最终的不一样,是否需要去反思下为什么呢?KPI 本身的设计,不就是为了让我们确认自己规划做的事情,最终是否实现了吗?
因此,即使未来某个时候我们的职业方向会进行调整,此时此刻我们一样需要对此进行规划。通过规划我们才有了目标,有了目标,我们才会制定计划并为之努力实现。
扬长避短很有效
其实我们每个人也都有各自擅长的部分,一般来说工作中更有效的方式是扬长避短,而不是花很多时间去补齐短板。我们常常会听到其他人说,“你没做过这些、要去挑战自己”,挑战自己的确是需要的,多尝试去做一些事情也总是好的。
如果我们需要在这场竞争中生存下来,必须拥有自己的不可替代性,也称之为技术壁垒。如果我们有擅长的领域,不妨尝试去深挖这样的领域,这样是一个相对容易的选择。
很多时候,也正是因为热爱和喜欢这些领域,我们才愿意投入更多的精力,因此在某种程度上也会更擅长。而做自己喜欢的事情的时候,即使再忙再苦再累,也一样会觉得很开心和值得。相反,如果做着不喜欢的工作时,每时每刻都是一种煎熬,每天上班就像去上坟。
可以的话,找一个可以发挥你自身优势的地方,那样的你会闪闪发光,你也会因此爱上你自己。
你的出处并不能代表什么
我刚进入互联网的时候,非科班出身、缺乏开发经验,自学了一周多就疯狂投简历。找工作很头疼,即使是裸辞的一番热血,再热烈也很容易被浇灭。最后虽然顺利找到了工作,但工资少得可怜。
那会从华为出来,待遇的落差总会不断地提醒我,到底是为了什么呢?但满怀的热情使得我每天上班充满干劲,下班后也继续在床上打着灯看书和写代码学习。那是 jQuery 横行的年代,似乎只需要掌握了它,你就能所向披靡。还有 CSS/CSS3 动画等,对 CSS 的掌握基本上是 10%的理解加上 90%的实践日积月累不断沉淀的。
那段时间可以感觉到成长很快,几位后台开发小哥哥带着入门,告诉我需要学习哪些知识、可以去哪些网站上学,然后就停不下来了。我曾经在面试的时候说自己学习能力很强,但是通常别人会问,你怎么证明呢?
不知道为什么,现在似乎大家多多少少都会不正视外包,“要不是能力不够也不会当外包”、“不能指望他们能学会什么”这样的话也经常会听到。可能是因为很多人的经历和体验里,都是比较顺畅阻力较少。而我也很荣幸曾经置于职业的低谷,使得很多时候能看到更多的可能性。
同样的,如今很多公司在招人的时候对学历的要求也越来越高,这是由于竞争市场资源过剩导致的,公司或许在性价比等方面考虑进行这样的调整,但我们不能自己限制住自己。我也见过一些特别厉害的开发,他们并不一定来自很好的学校。只是因为有着一股认真钻研的劲,他们看不到所谓的比较、竞争,专心致志地沉浸在自己的世界中,并做出了很多的成绩。
是否科班出身、是否外包出身、是否学历优秀,这些或许对其他人来说会有影响,但这些都不应该影响我们自身要去努力,不应该成为我们去给自身贴上一些标签的理由。
而如今大家都说什么寒冬到来、前端已死,要问我的想法,大概是世上无难事、只怕有心人罢了。
真正的热爱,从来不会因一份怎样的工作而受到影响,只不过如今大多数人更在意利益得失而已。
将目标放长放远
或许你会觉得制定计划不靠谱,因为事情永远都在变化。工作总是很复杂,不可控制的因素太多了。例如小明想要深入钻研浏览器渲染的方向,但实际上团队负责的业务都比较简单,因此小明常常需要快速上线某个新模块,节奏一直慢不下来,也完全没有机会和精力去研究自己的东西。
遇到这种情况,可以尝试将眼光再放长远一些。如果将职业规划比作一场马拉松,首先我们得确认目标是什么,是拿到前面的名次还是完成这场比赛?以前参加过中长跑的田径比赛,教练在比赛前会叮嘱我们几件事:
- 起跑的时候不要用力过猛,但需要让自己保持在一定的名次以内。
- 过程中可以选择排在前面节奏比较好的选手,紧跟在对方后面。领跑比跟跑更累,紧紧贴在对方身后可以让对方心理上有压力。
- 除了最后的冲刺,最好要保持匀速的节奏,因为变速跑会消耗更多的体力。
其实做职业规划和长跑很相似,我们需要确定一个较远的目标,然后控制好节奏、切忌着急和用力过猛。以我自己为例,一开始我想要往前端深度的领域发展,但我的起跑线是非科班+外包。显然,我无法一下子到达自己想去的地方,而此时自身的实力也无法和想要的岗位相匹配,因此我整体的职业路线是:外包公司前端 -> 中规模公司前端 -> 大公司重后台的业务部门前端 -> 大公司重前端业务部门前端。
这是一个经历了好些年的过程,每当我觉得在所在的团队中没法获得更多成长的时候,就会选择进入下一个阶段。如果目的很明确的话,你会清晰地知道自己什么时候该调整、接下来要去哪。
中间也遇到过一些团队,虽然团队中缺乏我想要的复杂大型前端业务项目,但团队会给道其他的机会,例如待遇上的回报、往管理方向发展带团队等等。很多条件都比较诱人,团队也的确给到了足够的诚意希望我留下来。但我知道自己想要的是前端领域的深挖,如果现在因为有其它诱惑而暂时选择放弃,以后遇到同样的困境是不是每次都会选择放弃呢?
因此,基本上我都选择了按照原目标继续往前走。有管理者觉得很疑惑,大家都往钱多的地方走,他问我是不是对钱没什么需要。我当时的回答是,把该学的知识和技能都掌握,如何赚钱它不该是我需要担心的问题。
将眼光放远一些,直到我们建立起自己的技术壁垒,在那之前即使挣到更多的钱、可以带团队干活,也依然可能会面临被这个行业抛弃。当然,这里的前提是我自身想要往技术的方向去发展。如果想要往管理方向去发展,一些带团队的经验也是很有帮助的。
如果现在的你距离自己的目标太远,那么不妨尝试找到去向最终目标的一个小目标,先往小目标去努力。通往目标的路上干扰很多,但如果你足够地坚定,总有一天也能去到自己想去的地方的。
职业发展中面临的选择
对于每个技术人来说,都会遇到一些发展方向的选择困惑,比如“该往深度发展”还是“该往广度发展”。前端也不例外,我们的发展方向种类越来越多,但一个人的精力总是有限的,我们还是需要做出选择。
全栈 or 纯前端?
如今随着 Node.js 的普及,也有不少的前端开发慢慢转型做全栈、大前端等方向。
的确,对于有全栈工作经验的人来说,找工作的时候会更吃香。但我们日常工作中是否都有机会去接触后台开发、客户端开发这些内容呢?是否一定需要有这样的工作经验才能获得更好的发展呢?
很多时候,前端由于门槛较低,很多的前端开发(比如我)都不是计算机专业出身。我们对于计算机基础、网络基础、算法和数据结构等内容掌握很少,更多时候是这些知识的缺乏阻碍了我们在程序员这一职业的发展,这也是为什么很多前端开发苦恼自己到达天花板,想着转型全栈或者后台就能走得更远。
这其实是个误区。后台开发由于开发语言、服务器管理、计算机资源等工作内容的不一致,对于专业基础的要求更高,因此看上去似乎比前端能走得更远。但随着成熟的解决方案的出现,像分布式部署和管理、全链路跟踪等,以及运维和 DBA 等职位的出现、后台基本框架的完善,更多的后台开发技术选型的范围不大,在开发过程中也同样会偏向业务开发,因此更多的关注点会落在业务风险梳理、问题定位和追踪、业务稳定性、效率提升等地方。对于全栈开发中的后台开发,可能涉及的内容会更加局限一些。
所以,其实我们在日常工作中也可以更多地关注后台的实现和能力,除了可以更好地配合和理解后台的工作外,还可以提升自己对后台工作内容的理解。当然,最重要的依然是扎实地补充计算机基础知识。
全栈开发经验可能让我们更容易地找到工作,但只有基础知识的掌握足够深入,才可以在接触后台开发、终端开发等内容的时候,有足够的能力去快速高效地解决问题。
相比转型全栈,其实纯前端可深挖的方向也很多,包括关注性能的各种深入的性能优化领域、关注效能的脚手架/CI/CD 等构建领域、关注可维护的项目与代码设计等架构领域、关注浏览器渲染的游戏引擎/WebGL 等特殊领域。选择走广度方向会要求有足够丰富的项目经验,而选择走深度方向只需要在某个领域有足够深刻的理解和突破,就可以建立起稳固的技术壁垒。
ToB or ToC
对于前端同学来说,我们也常常会纠结与 ToB 和 ToC 的工作内容选择,它们之间区别多在于用户群体和数量。
一般来说,ToB 的业务服务于某一类用户群体,因此会根据服务对象的不一样,工作重点有所区别。例如,如果服务于银行,会对技术方案/安全性要求严格;如果服务于政府机构,则可能需要兼容较低版本的 IE 浏览器(笑),技术选型比较局限。但通常来说,ToB 业务的用户量并不会特别大,对性能要求较低,有些情况下也会由于机器部署环境封闭的原因,对网络和安全性要求较低,因此 ToB 业务可以更多关注开发效率提升、技术管理选型、项目可维护性等方面。
ToC 的业务用户量较大,对加载性能、浏览器兼容性等都要求很高,因此常常需要进行性能优化、兼容性检测、实时监控、SEO 优化等工作。
找工作的时候,拥有 ToC 业务开发经验通常会比拥有 ToB 业务开发经验的优势要大一点,因为 ToC 对前端的各个角度要求都相对较高。但在真正的工作中,由于精力和工作内容分配的问题,很多参与 ToC 业务的人更多只会关注到自己负责的模块部分,因此很多时候并没有掌握到较完整的 ToC 业务相关的关键技术方案。同样,即使是在做的是 ToB 业务,也有不少小伙伴会有很多时间去研究一些新技术、做很多的选型调研,也可以在这个过程中获得很好的成长。
所以,决定我们能否掌握更多的、成长更快的,或许业务的影响比我们想象中还要小,最终还是取决于自己。
赚钱 or 个人成长?
当一份很赚钱但没什么技术含量的工作(下面成为工作 A),以及一份有趣又具备足够挑战性的工作(工作 B),这样两份工作放在我们面前的时候,大概很多人都会犹豫。这的确是一个很现实的问题,钱可以让我们买到很多自己想要的东西,但它却没法买来成长极快的工作经历。丰富的工作经历可以给我们带来竞争力,但短期内可能会带来经济上的困扰。
分析每个阶段的需求
前面我有表达过自己的观点,如果我们掌握了足够的技术和能力,就不会担心自己赚不到钱。如果以这个角度来看,工作 B 显然会是我们的选择。但这个世界并不都是非黑即白的,如果我们身边大多数的小伙伴都选择了向钱看,他们每年赚到的钱甚至是我们的一两倍,大多数人都无法不为所动。当然,如果有一份工作又能成长又能赚钱的工作最好,但遇到这样的选择概率会很低。
我们可以将自己的职业发展分为几个阶段,然后针对每个阶段分析该阶段中最重要的一些目标,这些目标可以是自身能力的提升,也可以是工资的上涨,还可以是职级的晋升等等。那么,当我们遇到困扰的选择时,可以选择当前阶段中比较重要的目标相关的工作内容。
举个例子,张三家境不好,他希望毕业工作之后可以尽快帮家里还清贷款,那么张三可以先选择赚钱更多的工作 A。当贷款还清以后,张三可以进入下一个阶段,如果这个阶段他觉得自己要提升实力来维持在工作中的竞争力,那么他就可以选择成长更快的工作 B。
和张三不同,李四只想攒点钱买个房子,对他来说工作就只是一份工作。但如果他不提升自己的能力,或许就会面临被淘汰、也没法赚到足够的钱,因此李四可能需要在某个阶段选择更具挑战性的工作 B。
每个人的愿望都不一样,有些人希望攒一些积蓄、买个小房子、过点小日子,也有人希望在职场叱咤风云、留下自己的名字,还有人希望沉浸在自己的世界、一直钻研某个领域。我们的愿望决定了我们最终的目标,而为了实现这个目标,中间也可能会做些看起来与目标相背离的事情。
我们在做的事情到底有没有用、能不能到达想去的远方,这些只有时间能证明。很多时候,每个人看到的只有当下的片刻,我们不能因为现在眼里的自己不像自己,就感到不甘、难过、想要自暴自弃。同样也不能因为目前眼里其他人的趋利避害、趋于世俗而瞧不起对方。或许有些人我们无法理解也无法接受,但即使认为不是一路人,也该给予他们足够的尊重。
为什么不可以一边赚钱一边做喜欢的事情呢
大多数人都存在这样的误区,认为做自己喜欢的事情就很幸运了,不应该再期望能赚到多少钱。
我也看到有些人为了追求自己想做的工作,愿意“不要工资”、“只要给我做的机会就好了”。做自己喜欢的事情固然很好,但这并不意味着我们必须要付出很多很多的代价。从公司的角度看,会因为一个人零成本而录用他的几率不大,更多的时候还是愿意付出更多的成本招聘一个有足够能力的人。如果想要争取一份工作,我们要做的是努力提升自己、让自己配得上这份工作的职责要求。
当然,也有人是因为想要转行,认为自己没有相关的工作经历,被录用的概率太低,认为如果自己不要钱对方可以给自己机会去学习就足够了。对于这种想法,我依然保持上述的建议:尽可能先提升自己的能力,通过自学也好,出去从有所关联的小职位、小公司开始做起也都是可以的。不需要提出不要工资这样的条件,这样只会更让对方认为你能力欠缺。
有些时候,我们还会陷入另外一个误区:如果因为做自己喜欢做的事情而获利,这种喜欢就不纯粹了。但谁能告诉我,为什么我们不能一边做自己喜欢的事情一边赚钱呢?如果我们做自己喜欢的事情,同时还能赚到钱,那不是会让自己更有动力、有更多的成本去继续做这些喜欢的事情吗?
]]>