
前端入门6--认识浏览器
更新日期:
《前端入门》系列主要为个人对前端一些经验和认识总结。本节我们从用户角度出发,认识浏览器的渲染机制吧。
浏览器
浏览器的主要功能是展示网页资源,也即请求服务器并将结果显示在浏览器窗口中。
资源的格式一般是HTML,但也有PDF、图片等其它各种格式。资源的定位由URL来实现。
浏览器的结构
废话少说,先上图: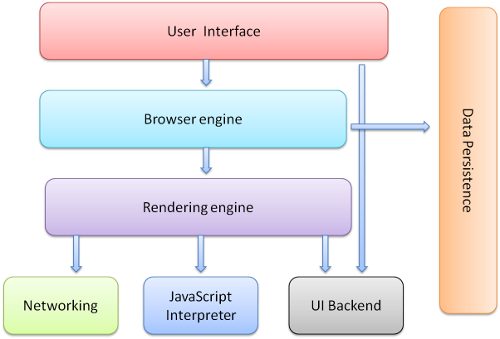
用户接口(User Interface)
包括地址栏,前进后退,书签菜单等窗口上除了网页显示区域以外的部分。浏览器引擎(Browser engine):查询与操作渲染引擎的接口。
渲染引擎(Rendering engine)。
负责显示请求的内容,比如请求到HTML, 它会负责解析HTML与CSS并将结果显示到窗口中。网络(Networking)。
用于网络请求, 如HTTP请求。它包括平台无关的接口和各平台独立的实现。UI后端(UI backend)。
绘制基础元件,如组合框与窗口。它提供平台无关的接口,内部使用操作系统的相应实现。JavaScript解释器(JavaScript Interpreter):用于解析执行JavaScript代码。数据存储(Data storage)。
这是一个持久层。浏览器需要把所有数据存到硬盘上,如cookies。
新的HTML规范 (HTML5) 规定了一个完整(虽然轻量级)的浏览器中的数据库:web database。
以上大概是浏览器的主要结构,作为前端,除了大致都了解一下之外,这节我们主要关注渲染引擎和JavaScript解释器。
当然,我们先从头理一下页面请求的过程。
页面请求
当我们去面试的时候,常常会被问一个问题:在浏览器里面输入url,按下 enter 键,会发生什么?
这是个或许平时我们不会思考的问题,不过在了解之后会对整个网页渲染有更好的认识。
当我们按下 enter 键之后,浏览器就会发起一个HTTP请求,我们也可以从控制台看到: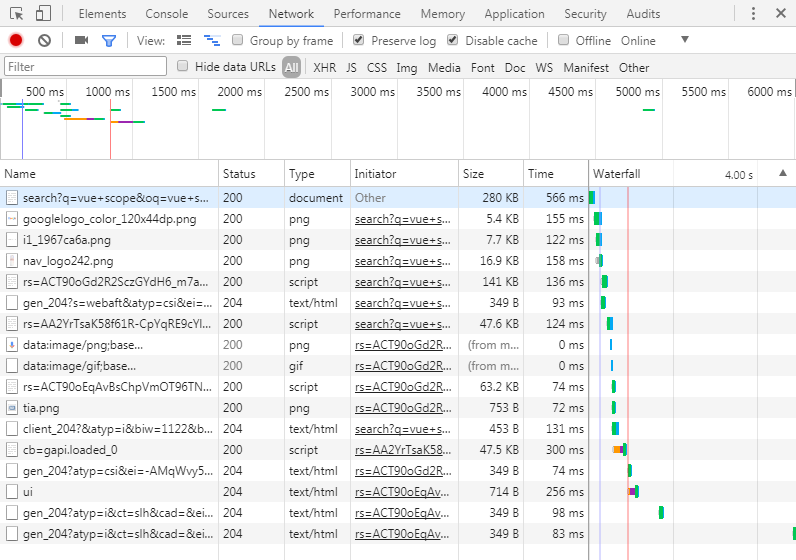
在这里,我们能看到所有浏览器发起的网络请求,包括页面、图片、CSS 文件、xhr 请求等等,还能看到请求的状态(200成功、404找不到、缓存、重定向等等)、耗时、请求头和内容、返回头和内容,等等等等。
这里涉及太多 http 相关的东西啦,先略过。
这里第一个就是我们的页面请求,我们来看看返回了什么:
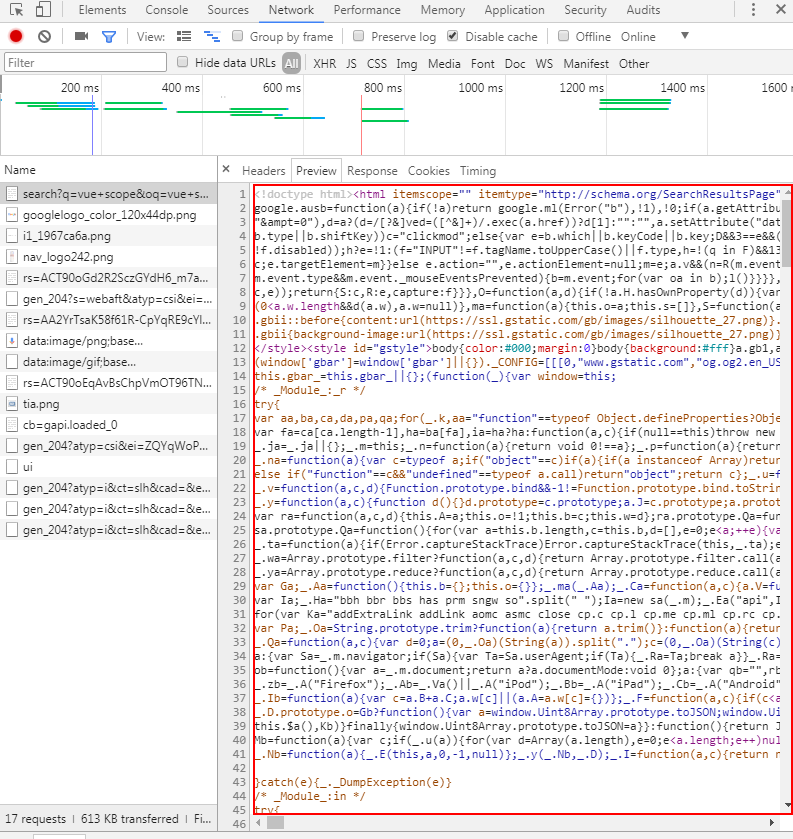
很明显,这里返回<html>页面,然后浏览器会加载页面,同时页面中涉及的资源也会触发请求下载,包括我们看到的png图片、js文件,这里没有css样式,大概是样式被直出到<html>页面里啦。
当然,这里面没有体现请求发送出去之后的流程,下面是一个完整的HTTP请求过程:
- 域名解析(此处涉及
DNS的寻址过程) - 发起
TCP的3次握手 - 建立
TCP连接后发起http请求 - 服务器响应
http请求,浏览器得到html代码 - 浏览器解析
html代码,并请求 html 代码中的资源(如js、css、图片等,此处可能涉及HTTP缓存) - 浏览器对页面进行渲染呈现给用户(此处涉及浏览器的渲染原理)
关于最后一步,我们先上个图:
这是我们的浏览器拿到源代码后,会进行的处理。
上面这些环节,如果你还有哪些不是很清楚的,请抱着强烈的好奇心去把它们探索完成。
浏览器渲染机制
解析
我们亲爱的浏览器会解析三个东西:
HTML/SVG/XHTML。解析这三种文件会产生一个DOM Tree。(渲染引擎)CSS,解析CSS会产生CSS规则树。(渲染引擎)Javascript脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree。(JavaScript解释器)
解析完成后,浏览器引擎会通过DOM Tree和CSS Rule Tree来构造Render Tree。
大致流程如下图:
我们来看看它们都是些啥。
DOM Tree
前面也简单讲过 DOM 树了,这里再从《浏览器的渲染原理简介》偷一下(噢,上面东西也是很多从这偷…参考的):
1 | <html> |
上面的这段html会生成这样的一个DOM Tree: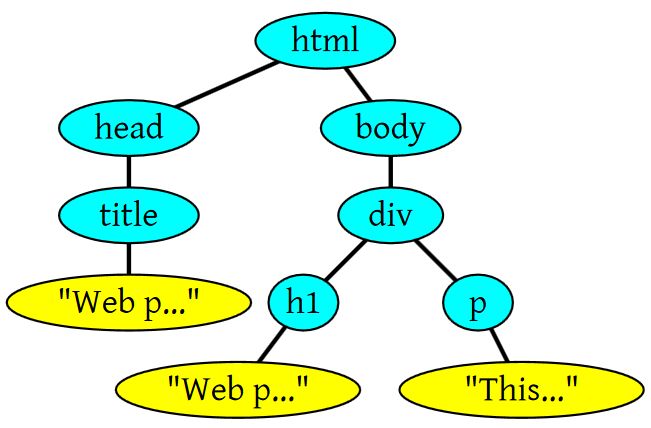
DOM Tree和Render Tree有个很简单的区别:像header或display:none的元素,会在DOM Tree中,但不会添加到Render Tree里。
Render Tree
CSS Rule Tree主要是 Firefox 的产物。
Firefox 基本上来说是通过CSS解析生成CSS Rule Tree,然后通过比对DOM生成Style Context Tree。
然后 Firefox 通过把Style Context Tree和其Render Tree(Frame Tree)关联上,就完成了。
Webkit 不像 Firefox 要用两个树来干这个,Webkit 也有Style对象,它直接把这个Style对象存在了相应的DOM结点上了。
建立CSS Rule Tree是需要比照着DOM Tree来的。CSS匹配DOM Tree主要是从右到左解析CSS的Selector,这是一个相当复杂和有性能问题的事情。
渲染
解析的角度大概讲完了,下面来从渲染的角度讲讲。
基本流程
渲染的流程基本上如下(黄色的四个步骤):
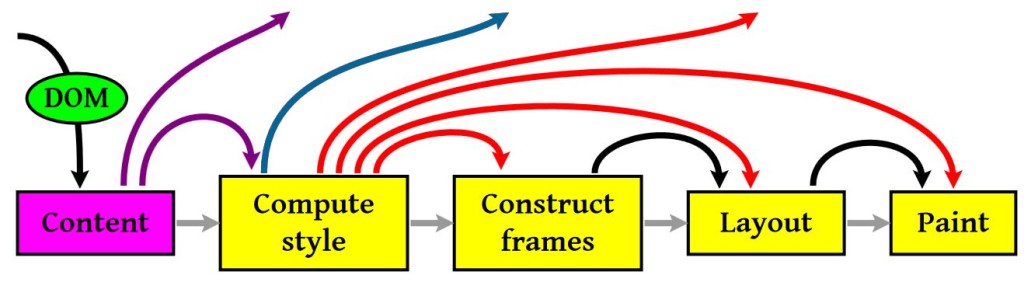
- 计算
CSS样式 - 构建
Render Tree Layout:定位坐标和大小,是否换行,各种 position, overflow, z-index 属性等等- 正式开画
重新Layout
图中有很多连接线,代表Javascript动态修改了DOM属性或是CSS属会导致重新Layout,有些改变不会,就是那些指到天上的箭头,比如,修改后的CSS rule没有被匹配到。
1. 重绘(Repaint)
屏幕的一部分要重画,比如某个CSS的背景色变了。但是元素的几何尺寸没有变。
2. 重排(Reflow)
元件的几何尺寸变了(Render Tree的一部分或全部发生了变化,Reflow或Layout),需要重新验证并计算Render Tree。HTML使用的是流式布局,如果某元件的几何尺寸发生了变化,需要重新布局,也就叫Reflow。
Reflow会从<html>这个root frame开始递归往下,依次计算所有的结点几何尺寸和位置,成本比Repaint的成本高得多的多。
所以我们要注意以下一些操作,因为可能会导致性能降低:
- 增加、删除、修改
DOM结点 - 移动
DOM的位置,或是搞个动画 - 修改
CSS样式 Resize窗口(移动端没有这个问题),或是滚动
了解这些以后,我们在写代码的时候就会下意识去比避免啦。当然,现在 MVVM 框架流行,以及 CSS3 普遍之后,手动操作DOM的场景也越来越少啦。
浏览器加载顺序
阻塞的 script 标签
正常的网页加载流程是这样的:
- 浏览器一边下载HTML网页,一边开始解析
- 解析过程中,发现
<script>标签 - 暂停解析,网页渲染的控制权转交给
JavaScript引擎 - 如果
<script>标签引用了外部脚本,就下载该脚本,否则就直接执行 - 执行完毕,控制权交还渲染引擎,恢复往下解析
HTML网页
将js放在body的最后面,可以避免资源阻塞,同时使静态的html页面迅速显示。
如果外部脚本加载时间很长(比如一直无法完成下载),就会造成网页长时间失去响应,浏览器就会呈现“假死”状态,这被称为“阻塞效应”。html需要等head中所有的js和css加载完成后才会开始绘制,但是html不需要等待放在body最后的js下载执行就会开始绘制。
将css放在head里,可避免浏览器渲染的重复计算。
经过上面的渲染过程,我们知道Layout的计算是比较消耗性能的,所以我们在开始计算Render Tree之前,就把所有的css文件拿到,这样可减少Repaint和Reflow。
参考
结束语
这一节我们主要介绍了浏览器的主要结构、一些解析和渲染的机制。至于js文件的加载顺序、以及js代码的加载顺序等等,这里没有太多的讲解,小伙伴们可以自行去研究一下。

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢