
9102全员学Vue--1.如何理解前端和Vue
更新日期:
最近身边学习 Vue 的人也越来越多了,大家都有很多的疑问,为什么前端要用框架、Vue 做了些什么、要怎么上手,等等。距离上一次写 Vue 也过去三年了,是时候再把这三年自己的理解再整理进去了。由于这个系列主要是希望写给可能前端掌握也不深的人,所以会铺垫一些自己认为需要的内容,本节先来讲讲入门前端,作为铺垫,来理解 Vue 这个框架吧。
前端页面解析
页面组成
我们打开一个前端项目,经常会看到很多不同后缀的文件,例如一个页面可能包括a.html、a.css、a.js,用了 Vue 还有a.vue,再加上 Typescript 可能还有a.ts。
相信有些没写过前端的开发们是有点崩溃的,我们先来分别看看一个前端页面都是由什么组成的。其实最终跑在浏览器中的代码,主要包括三种:HTML、CSS、Javascript。
HTML
直接从代码说起,最简单的莫过于:1
2
3
4
5
6
7<html>
<head></head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
这里面包括两个子模快:
<head>:常包括控制样式的<link>标签、控制浏览器特殊逻辑的<meta>标签、控制代码执行逻辑的<script>,不展示到页面。<body>:包括展示在页面的内容。
通常来说,一段 HTML 代码,最终在浏览器中会生成一堆 DOM 节点树,例如:1
2
3
4<div>
<a>123</a>
<p>456<span>789</span></p>
</div>
这段代码在浏览器中渲染时,其实是长这个样子的: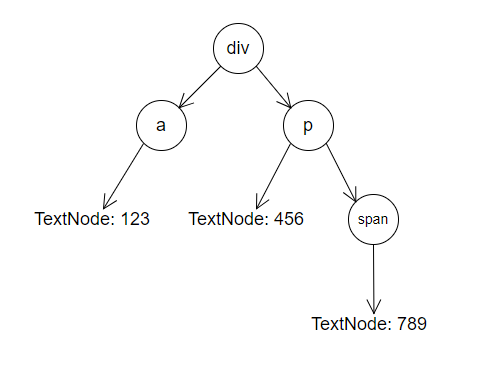
这不一定是最终的结果,因为我们还可以这样操作:
- 通过 CSS 样式,例如
display: none来让其中某个节点消失。 - 通过 JS 代码操作 DOM,例如使用
document.getElementById获取到某个节点元素,然后再通过设置.innerHTML来改变元素的内容。
CSS
CSS 主要是给我们的 HTML 元素添加样式,可以通过几个方式匹配:
- DOM 元素匹配:例如
p{color: red}会让所有<p>元素的文字都变成红色 - class 匹配:类的匹配,例如
.color-red{color: red}会让所有<xxx class="color-red">元素的文字都变成红色 - id 匹配:id标识符的匹配,例如
#color-red{color: red}会让<xxx id="color-red">元素的文字都变成红色(若页面内有多个相同的 id,则只有第一个生效)
CSS 的调试和编写上手不简单,会需要很多的踩坑和练习,它也不像 JS 那样可以完全根据语法或是逻辑理解,总有兼容性会颠覆你之前的认知。不过 CSS 写好了,对写页面的效率会有很大的提升。
Javascript
HTML 是简单的网页静态信息,而 JavaScript 可以在网页上实现复杂的功能。
我们常常使用 Javascript 来做以下事情:
- 处理事件(点击、输入等)
- 改变 HTML 内容、位置和样式
- 处理 Http 请求、各种业务逻辑的执行
- 很多其他的事情也可以做
Javascript 是单线程的,更多是因为对页面交互的同步处理。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作 DOM,若是多线程会导致严重的同步问题。
关于更多的 Javascript,可以阅读《前端入门5–Javascript》。
页面渲染
浏览器的渲染机制
我们现在知道一个页面的代码里,主要包括了 HTML、CSS、Javascript 三大块内容,那么浏览器是怎么解析和加载这些内容的呢?
一次浏览器的页面渲染过程中,浏览器会解析三种文件:
- 解析 HTML/SVG/XHTML,会生成一个 DOM 结构树
- 解析 CSS,会生成一个 CSS 规则树
- 解析 JS,可通过 DOM API 和 CSS API 来操作 DOM 结构树和 CSS 规则树
CSS 规则树与 DOM 结构树结合,最终生成一个 Render 树(即最终呈现的页面,例如其中会移除 DOM 结构树中匹配到 CSS 里面display:none的 DOM 节点)。一般来说浏览器绘制页面的过程是:
- 计算 CSS 规则树。
- 生成 Render 树。
- 计算各个节点的大小/position/z-index。
- 绘制。
更多的资料,大家可以参考《浏览器的渲染原理简介》,或者英文很棒的你也可以阅读原文《How browsers work》
页面的局部刷新
一般看来,浏览器生成了最终的 Render 树,页面也已经渲染完毕,似乎浏览器已经完成了它的工作了。但现实中我们的页面更多的不只是静态的页面,还会包括点击、拖拽等事件操作,以及接口请求、数据渲染到页面等动态的交互逻辑,这时候我们会需要更新页面的信息。
我们的业务代码中情况会复杂得多,除了插入内容,还包括内容更新、删除元素节点等。不管是那种情况,目前来说前端一般分为两种方式:
- 绑定映射表方式。
- 直接替换内容方式。
1. 绑定映射表方式
这其实是挺经常使用的一种方式,例如下面这段代码:1
var a = document.getElementById('a');
这里拿到了<xxx id="a">的这样一个元素映射,我们在更新内容、处理节点的时候就可以用这个映射来直接操作,如:1
2
3
4
5
6// 1. 更改元素里面内容
a.innerHTML = '<p>测试</p>'
// 2. 插入一个<a>元素
a.appendChild(document.createElement(`a`))
// 3. 删除第一个元素,在这里是前面的<p>测试</p>
a.removeChild(a.firstChild)
如果我们一个页面里需要绑定变量的元素很多,那每次要更新某块的页面数据,可能会需要保存很多的元素映射,同时需要调用很多很多的createElement()/appendChild()/removeChild()这类方法,也是个不小的开销。这种情况下,我们可以使用直接替换内容的方式。
2. 直接替换内容方式
我们每次更新页面数据和状态,还可以通过innerHTML方法来用新的HTML String替换旧的,这种方法写起来很简单,无非是将各种节点使用字符串的方式拼接起来而已。
例如,上面的几次更新 a 元素节点,可以调整成这样实现:1
2
3
4
5
6// 1. 更改元素里面内容
a.innerHTML = '<p>测试</p>'
// 2. 插入一个<a>元素
a.innerHTML = '<p>测试</p><a></a>'
// 3. 删除第一个元素,在这里是前面的<p>测试</p>
a.innerHTML = '<a></a>'
这种方式来更新页面简单粗暴,但是如果我们更新的节点范围比较大,这时候我们需要替换掉很大一片的HTML String。这种情况下,会面临着可能导致更多的浏览器计算。
页面回流、重绘
前面也介绍了,浏览器绘制页面的过程是:1.计算CSS规则树 => 2.生成Render树 => 3.计算各个节点的大小/position/z-index => 4.绘制。其中计算的环节也是消耗较大的地方。
我们使用 DOM API 和 CSS API 的时候,通常会触发浏览器的两种操作:Repaint(重绘) 和 Reflow(回流):
- Repaint:页面部分重画,通常不涉及尺寸的改变,常见于颜色的变化。这时候一般只触发绘制过程的第4个步骤。
- Reflow:意味着节点需要重新计算和绘制,常见于尺寸的改变。这时候会触发3和4两个步骤。
在 Reflow 的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成 Reflow 后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为 Repaint。
回流的花销跟render tree有多少节点需要重新构建有关系,这也是为什么前面说使用innerHTML会导致更多的开销。所以到底是使用绑定映射表方式,还是使用直接替换内容方式,都是需要具体问题具体分析的。
事件驱动
事件驱动其实是前端开发中最容易理解的编码方式,例如我们写一个提交表单的页面,用事件驱动的方式来写的话,会是这样一个流程:
- 编写静态页面。
1 | <form> |
- 给对应的元素绑定对应的事件。例如给 input 输入框绑定输入事件:
1 | var nameInputEl = document.getElementById('name-input'); |
- 事件触发时,更新页面内容:
1 | var nameValueEl = document.getElementById('name-value'); |
以上这个流程,是很常见的前端编码思维,我们称之为事件驱动模式。
前端思维转变
很多人不理解这几年来前端的变化,为什么不能再用 jQuery 统一天下呢?为什么要搞那么多的库,还要按照环境呢?不是用个 txt 编辑器就能写完一个页面吗,前端弄那么复杂是为了什么呢?
既然称之为思维转变,那么可以将事件驱动的思维模式作为过去常见的一种方式,而如今的前端开发过程中,多了很多的新框架、新工具,还有了工程化,这些带来了怎样的思维模式的转变呢?
前端框架的出现
其实最初是 AngularJS 开始占领了比较多的地位,后面 React 迎面赶上,在 Angular 断崖升级的帮助下,Vue 结合了各种框架的优势,以及非常容易入门的文档,成功成为了那一匹黑马。既然这一系列写的是 Vue 的入门和使用,那这里当然是基于 Vue 来介绍了。
数据绑定
Vue 文本插值
在 Vue 中,最基础的模板语法是数据绑定,例如:1
<div>{{ data }}</div>
这里绑定了一个 msg 的变量,开发者在 Vue 实例 data 中绑定该变量:1
2
3
4
5new Vue({
data: {
data: '测试文本'
}
})
最终页面展示内容为<div>测试文本</div>。
数据绑定的实现
这种使用双大括号来绑定变量的方式,我们称之为数据绑定。它是怎么实现的呢,数据绑定的过程其实不复杂:
- 解析语法生成 AST。
- 根据 AST 结果生成 DOM。
- 将数据绑定更新至模板。
上述这个过程,是模板引擎在做的事情。我们来看看上面在 Vue 里的代码片段<div>{{ data }}</div>,我们可以解析后获得这样一个 AST 对象:
1 | thisDiv = { |
这样,我们在生成一个 DOM 的时候,同时添加对data的监听,数据更新时我们会找到对应的nodeIndex,更新值:
1 | // 假设这是一个生成 DOM 的过程,包括 innerHTML 和事件监听 |
关于模板引擎更多的情况,可以查看《前端模板引擎》。
虚拟 DOM
虚拟 DOM 如今已经被作为前端面试基础题了,多多少少面试者都要去了解下,当初 React 就是因为虚拟 DOM 的提出,暂时赢下了浏览器性能之争。当然,这都是几年前的事情了,如今几大框架的性能问题,早也不是什么大问题了。
虚拟 DOM 大概是这么个过程:
(1) 用 JS 对象模拟 DOM 树,得到一棵虚拟 DOM 树。
(2) 当页面数据变更时,生成新的虚拟 DOM 树,比较新旧两棵虚拟 DOM 树的差异。
(3) 把差异应用到真正的 DOM 树上。
为什么要用到虚拟 DOM 呢?这是因为一个 DOM 节点它包括了太多太多的属性、元素和事件对象,感觉有上百个。但是我们并不是全部都会用到,通常包括节点内容、元素位置、样式、节点的添加删除等方法,而我们通过用 JS 对象表示 DOM 元素的方式,大大降低了比较差异的计算量。
虚拟 DOM 中,差异对比也是很关键的一步,这里简单说一下。当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异。通常来说这样的差异需要记录:需要替换掉原来的节点、移动、删除、新增子节点、修改了节点的属性、 对于文本节点的文本内容改变。经过差异对比之后,我们能获得一组差异记录,接下里我们需要使用它。
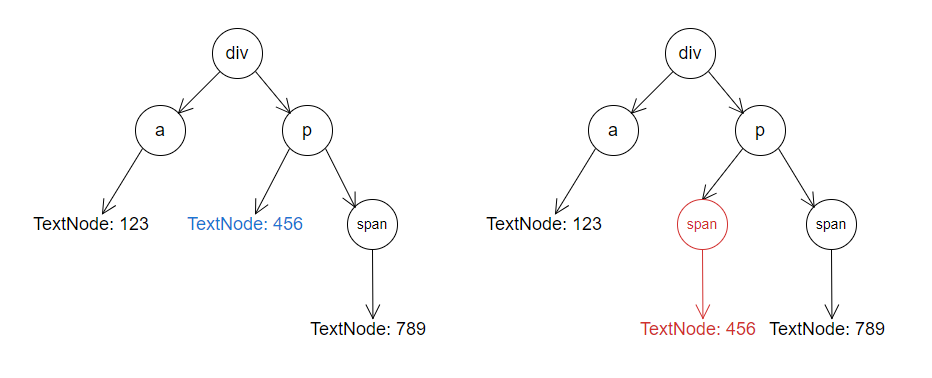
如图,这里我们对比两棵 DOM 树,得到的差异有:p 元素插入了一个 span 元素子节点,然后原先的文本节点挪到了span 元素子节点下面,最后通过 JS 操作就可以实现完。
XSS 漏洞
模板引擎还可以协助预防下 XSS 相关漏洞。我们知道,XSS 的整个攻击过程大概为:
- 通常页面中包含的用户输入内容都在固定的容器或者属性内,以文本的形式展示。
- 攻击者利用这些页面的用户输入片段,拼接特殊格式的字符串,突破原有位置的限制,形成了代码片段。
- 攻击者通过在目标网站上注入脚本,使之在用户的浏览器上运行,从而引发潜在风险。
避免 XSS 的方法之一主要是将用户所提供的内容进行过滤,而大多数模板引擎会自带 HTML 转义功能。在 Vue 中,默认的数据绑定方式(双大括号、v-bind等)会进行 HTML 转义,将数据解释为普通文本,而非 HTML 代码。
当然,如果你一定要输出 HTML 代码,也可以使用v-html指令输出。官方文档也有特殊说明:
你的站点上动态渲染的任意 HTML 可能会非常危险,因为它很容易导致 XSS 攻击。请只对可信内容使用 HTML 插值,绝不要对用户提供的内容使用插值。
关于 XSS 漏洞,更多的可以查看《前端安全系列(一):如何防止XSS攻击?》一文。
Vue简介
看看这些模板引擎都做了啥事,原本就是一个<div>,经过 AST 生成一个对象,最终还是生成一个<div>,这是多余的步骤吗?不是的,在这个过程中我们可以实现一些功能:
- 排除无效 DOM 元素,并在构建过程可进行报错
- 使用自定义组件的时候,可匹配出来
- 可方便地实现数据绑定、事件绑定等,具备自动更新页面的功能
- 为虚拟 DOM Diff 过程打下铺垫
- HTML 转义(预防 XSS 漏洞)
所以 Vue 它只是一个模板引擎吗?怎么说呢,模板引擎可能是我们选择框架的原因里最重要的一个,毕竟如果没有框架的话,所有上述这些很好用的能力都需要自己搭建,不然开发效率会很受影响。
我们看看 Vue 官方的介绍:
Vue 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。
关于 Vue 和其他框架的对比,可以看看官方文档-对比其他框架。易于上手这块,是大多数人都比较认可的,框架的性能也不错,这也是技术选型中比较重要的一些考虑。
数据驱动
前面也介绍了,在 jQuery 年代,我们通常是使用事件驱动的模式去进行开发了。那么使用了 Vue 之后,写代码的方式会有哪些不一样吗?
既然前面介绍了事件模型一般的编码流程,我们再来看看,同样的们写一个提交表单的页面,用数据驱动的方式来写的话,会变成这么一个流程:
- 设计数据结构。
1 | // 包括一个 name 和 一个 email 的值 |
- 把数据绑定到页面中需要使用/展示的地方。
1 | <form> |
- 事件触发时,更新数据。
1 | export default { |
我们在设置数据(this.name = event.target.value)的时候,Vue 已经替我们把将数据更新到页面的逻辑处理了。大家也可以去 codepen 或者 jsfiddle、stackblitz 这些在线编码网站上尝试下。
所以事件驱动和数据驱动一个很重要的区别在于,我们是从每个事件的触发开始设计我们的代码,还是以数据为中心,接收事件触发和更新数据状态的方式来写代码。
页面编写
如果要问,vue 和 jQuery 有什么不一样?其实它们从定位到设计到实现上都完全不一样,但是对开发者来说,我们可以做个简单直观的区别:1
2
3
4
5
6
7
8
9
10
11
12
13<!--1. jQuery + 事件驱动-->
<input type="text" id="input" />
<p id="p"></p>
<script>
$('#input').on('click', e => {
const val = e.target.value;
$('#p').text(val);
})
</script>
<!--2. vue + 数据驱动-->
<input type="text" v-model="inputValue" />
<p>{{ inputValue }}</p>
当我们在 Vue 中,模板引擎帮我们处理了模板渲染、数据绑定的过程,我们只需要知道这里面只有一个有效数据,即输入框的值。
页面抽象
既然使用了数据驱动,那么对页面的一个抽象能力也是很重要的。例如我们现在要写一个列表,数据从后台获取到之后,展示到页面中。
当我们需要渲染成列表时:
1
2
3
4
5
6
7
8
9
10
11
12
13<!--1). jQuery + 事件驱动-->
<ul id="ul"></ul>
<script>
const dom = $('#ul');
list.forEach(item => {
dom.append(`<li data-id="${item.id}"><span>${item.name}</span>: <a href="${item.href}">${item.href}</a></li>`)
});
</script>
<!--2). vue + 数据驱动-->
<ul>
<li v-for="item in list" :key="item.id"><span>{{item.name}}</span><a :href="item.href">{{item.href}}</a></li>
</ul>当我们需要更新一个列表中某个 id 的其中一个数据时(这里需要更改 id 为 3 的 name 值):
1 | // 1). jQuery + 事件驱动 |
在使用数据驱动的时候,模板渲染的事情会交给框架去完成,我们需要做的就是数据处理而已。那么转换了数据驱动之后,有什么好处呢?
当我们把一个页面抽象成数据来表示之后,可以做的事情就多了。如果我们把所有的页面、组件、展示内容和接口配置等都变成了配置数据,那么我们就可以把所有的东西都进行配置化。以前也写过一篇《组件配置化》,另外在玩 Angular 的时候也做过类似的设计,包括组件的配置–通过配置生成表单和页面应用的配置–通过配置生成管理端。当然,Vue 也完全可以做这种事情的,配置化的难度常常不在于技术有多难,而在于怎么把业务进行适当的抽象。
前端工程化
其实前端工程化这块,我并不是能理解得很深刻,能讲给大家的,应该只是自己的一种理解了。一般来说,现在的主流构建工具应该是 Webpack,包括我们使用 Vue 官方脚手架生成的代码,构建工具也是 Webpack。
我们在代码中会使用到很多的资源,图片、样式、代码,还有各式各样的依赖包,而打包的时候怎么实现按需分块、处理依赖关系、不包含多余的文件或内容,同时提供开发和生产环境,包括本地调试自动更新到浏览器这些能力,都是由 Webpack 整合起来的。
npm 依赖包
要实现工程化,前端开发几乎都离不开 nodejs 的包管理器 npm,比如前端在搭建本地开发服务以及打包编译前端代码等都会用到。在前端开发过程中,经常用到npm install来安装所需的依赖。
为什么会有 npm 包的出现呢?因为一个人的力量是有限的,我们在写代码的时候,为了可以将注意力集中到业务开发中,会需要使用别人开源的很多工具、框架和代码包。在很早以前,我们是一个个地下载,或是通过<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>的方式去引用。
当一个网站依赖的代码越来越多,其实管理依赖和版本是一件很麻烦的事情。然后 npm 就出现了,作为一个把这些代码集中到一起来管理的工具。
同时,我们可以结合一些 tree shaking 的能力,在本地构建的时候,把使用的别人的依赖包里没用用到的部分去掉,减小代码包的大小等。
在安装 Node.js 的时候,npm 的能力也会一块提供到,按照完之后就能直接在机器终端使用npm install xxx这种能力啦,需要安装什么依赖包呢,你可以去npmjs官网搜一下,也可以自己发布一些包供别人使用,例如之前我也写过一个v-select2-component组件。
vue cli
通常来说,脚手架可以让你快速地生成示例代码、搭建本地环境,也可以更新依赖的版本等,避免了每个开发者自行调整开发环境、打包逻辑等配置。
Vue cli 也提供了这样的能力,更多的可以参考官方文档。
Vue CLI 致力于将 Vue 生态中的工具基础标准化。它确保了各种构建工具能够基于智能的默认配置即可平稳衔接,这样你可以专注在撰写应用上,而不必花好几天去纠结配置的问题。
使用方式很简单:1
2
3
4// 安装脚手架
npm install -g @vue/cli
// 脚手架生成 vue 项目,同时会自动安装依赖
vue create vue-cli-demo
生成之后的代码目录是这样的: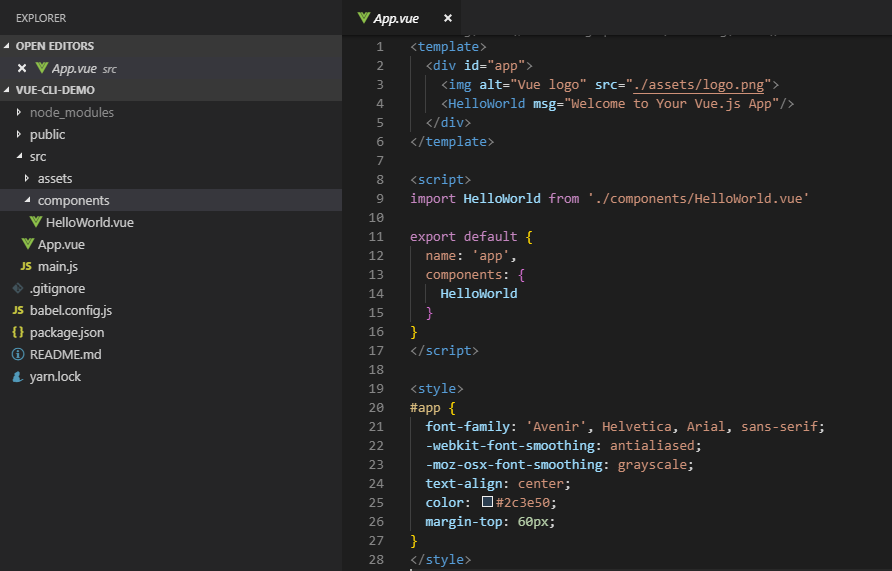
启动项目
一般来说,项目会有个 README.md 文件,你能看到一些简单的说明,例如这里生成的:1
2
3
4
5
6
7
8
9
10
11
12
13
14# Project setup
yarn install
# Compiles and hot-reloads for development
yarn run serve
# Compiles and minifies for production
yarn run build
# Run your tests
yarn run test
# Lints and fixes files
yarn run lint
yarn 跟 npm 都是差不多的包管理器,区别在于 yarn 在安装时会速度更快(并行、离线等),以及版本统一管理的比较好。但如果你不是有特殊的喜好或者习惯,其实两个都可以用,例如这里的yarn run serve也可以用npm run serve来运行。
如果有些习惯不好的项目缺了 README,这种时候要怎么去启动一个项目呢?可以查看package.json文件:1
2
3
4
5
6
7{
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint"
}
}
一般来说,开发环境是dev、serve等,生产环境是build,scripts里是一些任务,运行命令npm run taskName就可以启动了。
上图中,我们可以看到任务已经启动了,访问输出的地址(这里是http://localhost:8080/或者http://10.40.120.53:8080/)就能看到我们的项目跑起来了。
结束语
第一 part 结束了,更多的内容还是前端相关。这些主要是这几年对页面渲染的一些新的理解,然后简单用脚手架启动了个 demo 项目。内容是按照自己觉得较清晰的逻辑展开来讲的,如果说你有更好的想法,或是发现我的描述中有哪些不到位的地方,也十分欢迎来交流。
工具始终是工具没错,但一个工具为什么受这么多人追捧,它到底解决了什么,你可以从中学习到什么,这些才是个人认为的在使用工具时候收获的很重要的东西。在 Vue 官方文档很完善的情况下,我来给你们补上文档以外的一些技巧和内容吧。

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢