
复杂渲染引擎架构与设计--1.收集与渲染
更新日期:
对于一般的渲染引擎来说,我们可以简单地拿到待渲染的数据,然后直接通过 Canvas/DOM/SVG 来将需要渲染的图形和内容渲染出来。
而在复杂场景下,比如需要自行排版的文本、表格和图形类,光是将要渲染的数据计算出来,便容易面临性能瓶颈,而对于样式多样、结构复杂的内容来说,绘制过程也同样会出现性能瓶颈。
本文我们主要针对 Canvas 绘制的场景,来考虑将绘制的流程分为收集和渲染两部分。
渲染数据的收集
很多时候,我们在后台数据库存储的只有图形的基本信息,对于需要排版计算的数据来说,则需要在拿到数据之后,再根据页面进行排版计算,完成后才能渲染到页面。
或许这样说会有些抽象,我们以表格的渲染为例来说明。
对于表格这样的产品来说,存储的往往是以单元格为基本单位的数据,如每个单元格的内容(可能是复杂的富文本、图片、图标结合)、样式(边框、背景色)、行列的宽高等。而在实际上页面渲染的时候,我们可能会根据行列宽高、每个单元格的边框线设置来绘制格子的布局。
除此之外,我们还可能需要考虑单元格内容是否会超出单元格,来判断是否需要截断渲染、是否需要换行显示等。这便要求我们需要对内容宽高进行测量,比如使用CanvasRenderingContext2D.measureText()测量文本宽度,这依赖了浏览器环境下的 API 能力。这意味着我们无法在后台提前计算好这些数据,因此无法通过提前计算来加速渲染过程。
于是,我们需要在前端拿到后台数据后,再进行相应的排版计算。
如果说一边计算一边绘制,则整个过程的耗时会比较长,用户也可能会看到绘制过程,该体验不是很友好。因此,我们可以在计算过程中,先把要最终绘制的数据结果先收集到一起,Canvas 绘制的时候则可以直接用。
收集与绘制的功能划分
我们可以根据绘制内容,划分为以下的收集器和渲染器:
- 线段数据收集和绘制(如表头、边框线等)
- 矩形数据收集和绘制(如背景色)
- 图像数据收集和绘制(如图片)
- 文本数据收集和绘制(如文字内容)
- 其他数据收集和绘制
可见,收集器和渲染器的类型是一一对应的,渲染器在渲染的时候,可以直接从对应的收集器类型中获取数据,然后绘制。
还需要考虑一种情况,即相同的收集器和不同的收集器类型里,绘制内容有重叠时,需要考虑绘制堆叠的顺序。举个例子,单元格的文字需要在背景色上面,也就是说单元格的绘制需要比背景色要晚。
这意味着我们在收集的时候,还需要给收集的数据添加堆叠顺序,在绘制的时候,则按照堆叠顺序先后绘制。我们可以将收集器分为多个,每个收集器定义堆叠顺序,相同堆叠顺序的数据收集到一起。
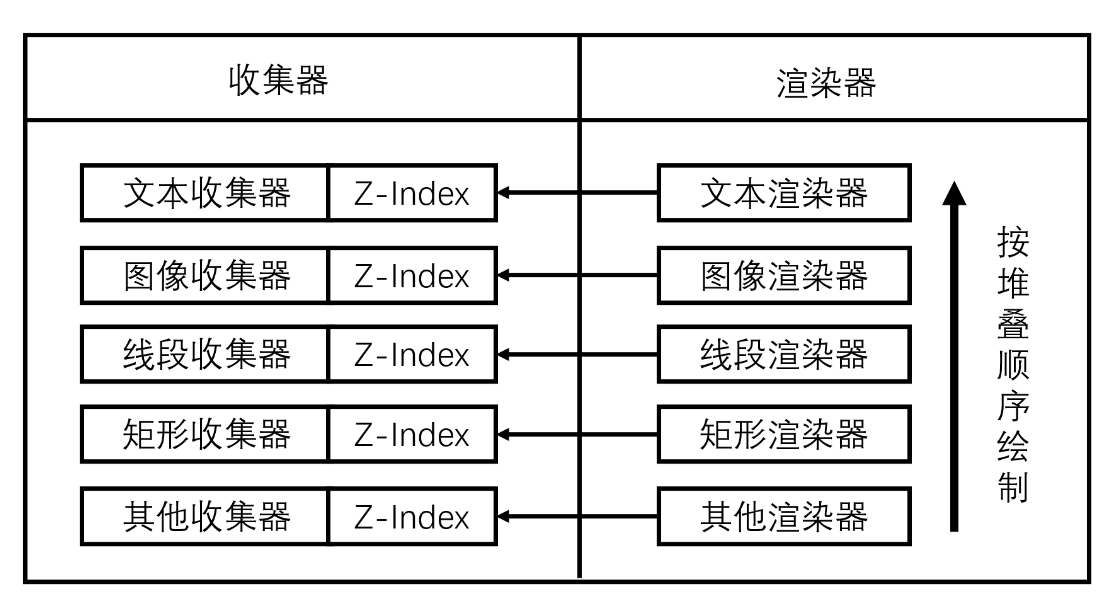
其实,我们使用一个收集器,通过给数据添加渲染类型,来将不同类型的数据放在一起,方便统一管理。在渲染的时候,则先根据绘制类型和堆叠顺序进行排序,再进行绘制。

渲染数据享元
前面我们在《前端性能优化–Canvas 篇》一文中描述过,Canvas 上下文切换的成本消耗比较大,如果在复杂内容绘制的情况下,可能会导致性能问题。
使用收集器的一个好处是,我们可以将同类型同样式的渲染数据进行享元。对于样式完全一样的数据,收集器可通过对样式进行 hash 享元存储在一起。
这样绘制的时候,就可以将样式一样的内容一起绘制,减少 Canvas 上下文的切换。
举个简单的例子,假设线段的绘制支持颜色、粗细两种不同的样式,那么我们收集的时候可以将同颜色、同粗细的线段位置信息存储在一起:
1 | class LineCollector { |
通过这样的方式,我们将要绘制的数据收集起来,方便 Canvas 进行更高效的渲染。
结束语
通过将 Canvas 渲染过程拆分为收集和渲染两部分,架构上更清晰的同时,在一定程度上提升了渲染的性能和效率。而这样的架构设计,也更方便后续做更多的拓展,我会在后续篇章继续介绍。

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢