
在线Excel项目到底有多刺激
更新日期:
加入腾讯文档 Excel 开发团队已经有好几个月了,刚开始代码下载下来 100+W 行,代码量很大但模块设计和代码质量比我想象中好好多了,今天跟大家分享下一个 Excel 项目到底可以有多好玩。
实时协同编辑的挑战
说到实时协同编辑的难点,大家的第一反应基本上是协同冲突处理。
冲突处理
冲突处理的解决方案其实已经相对成熟,包括:
- 编辑锁:当有人在编辑某个文档时,系统会将这个文档锁定,避免其他人同时编辑。
- diff-patch:基于 Git 等版本管理类似的思想,对内容进行差异对比、合并等操作,包括 GNU diff-patch、Myer’s diff-patch 等方案。
- 最终一致性实现:包括 Operational Transformation(OT)、 Conflict-free replicated data type(CRDT,称为无冲突可复制数据类型)。
编辑锁的实现方式简单粗暴,但会直接影响用户体验。diff-patch 可以对冲突进行自助合并,也可以在冲突出现时交给用户处理。OT 算法是 Google Docs 中所采用的方案,Atom 编辑器使用的则是 CRDT。
OT 和 CRDT
OT 和 CRDT 两种方法的相似之处在于它们提供最终的一致性。不同之处在于他们的操作方式:
- OT 通过更改操作来做到这一点
- OT 会对编辑进行操作的拆分、转换,实现冲突处理的效果
- OT 并不包括具体的实现,因此需要项目自行实现,但可以根据项目需要进行高精度的冲突处理
- CRDT 通过更改状态来做到这一点
- 基本上,CRDT 是数据结构,当使用相同的操作集进行更新时,即使这些操作以不同的顺序应用,它们始终会收敛在相同的表示形式上
- CRDT 有两种方法:基于操作和基于状态
OT 主要用于文本,通常常很复杂且不可扩展。CRDT 实现很简单,但 Google、Microsoft、CKSource 和许多其他公司依赖 OT 是有原因的,CRDT 研究的当前状态支持在两种主要类型的数据上进行协作:纯文本、任意 JSON 结构。
对于富文本编辑等更高级的结构,OT 用复杂性换来了对用户预期的实现,而 CRDT 则更加关注数据结构,随着数据结构的复杂度上升,算法的时间和空间复杂度也会呈指数上升的,会带来性能上的挑战。因此,如今大多数实时协同编辑都基于 OT 算法来实现。
版本管理
在多人协作的场景下,为了保证用户体验,一般会采用 diff-patch/OT 算法来进行冲突处理。而为了保证每次的用户操作都可以按照正确的时序来更新,需要会维护一个自增的版本号,每次有新的修改,都会更新版本号。
数据版本更新
数据版本能按照预期有序更新,需要几个前提:
- 协同数据版本正常更新
- 丢失数据版本成功补拉
- 提交数据版本有序递增
要怎么理解这几个前提呢?我们来举个例子。
小明打开了一个文档,该文档从服务器拉取到的数据版本是 100。这时候服务器下发了个消息,说是有人将该版本更新到了 101,于是小明需要将这个 101 版本的数据更新到界面中,这是协同数据版本正常更新。
小明基于最新的 101 版本进行了编辑,产生了个新的操作数据。当小明将这个数据提交到服务器的时候,服务器看到小明的数据基于 101 版本,就跟小明说现在最新的版本已经是 110 了。小明只能先去服务器将 102-110 的版本补拉回来,这是丢失数据版本成功补拉。
102-110 的数据版本补拉回来之后,小明之前的操作数据需要分别跟这些数据版本进行冲突处理,最后得到了一个基于 110 版本的操作数据。这时候小明重新将数据提交给服务器,服务器接受了并给小明分配了 111 版本,于是小明将自己本地的数据版本升级为 111 版本,这是提交数据版本有序递增。
维护数据任务队列
要管理好这些版本,我们需要维护一个用户操作的数据队列,用来有序提交数据。这个队列的职责包括:
- 用户操作数据正常进入队列
- 队列任务正常提交到接入层
- 队列任务提交异常后进行重试
- 队列任务确认提交成功后移除
这样一个队列可能还会面临用户突然关闭页面等可能,我们还需要维护一个缓存数据,当用户再次打开页面的时候,将用户编辑但未提交的数据再次提交到服务器。除了浏览器关闭的情况,还有用户在编辑过程中网络状况变化而导致的网络中断,这种时候我们也需要将用户的操作离线到本地,当网络恢复的时候继续上传。
房间管理
由于多人协同的需要,相比普通的 Web 页面,还多了房间和用户的管理。在同一个文档中的用户,可视作在同一个房间。除了能看到哪些人在同一个房间以外,我们能收到相互之间的消息,在文档的场景中,用户的每一个操作,都可以作为是一个消息。
但文档和一般的房间聊天不一样的地方在于,用户的操作不可丢失,同时还需要有严格的版本顺序的保证。用户的操作内容可能会很大,例如用户复制粘贴了一个10W、20W的表格内容,这样的消息显然无法一次性传输完。在这种情况下,除了考虑像 Websocket 这种需要自行进行数据压缩(HTTP 本身支持压缩)以外,我们还需要实现自己的分片逻辑。当涉及数据分片之后,紧接而来的还有如何分片、分片数据丢失的一些情况处理。
多种通信方式
前后端通信方式有很多种,常见的包括 HTTP 短轮询(polling)、Websocket、HTTP 长轮询(long-polling)、SSE(Server-Sent Events)等。
我们也能看到,不同的在线文档团队选用的通信方式并不一致。例如谷歌文档上行数据使用 Ajax、下行数据使用 HTTP 长轮询推送;石墨文档上行数据使用 Ajax、下行数据使用 SSE 推送;金山文档、飞书文档、腾讯文档则都使用了 Websocket 传输。
而每种通信方式都有各自的优缺点,包括兼容性、资源消耗、实时性等,也有可能跟业务团队自身的后台架构有关系。因此我们在设计连接层的时候,考虑接口拓展性,应该预留对各种方式的支持。
每个格子都是一个富文本编辑器
其实除了实时协同编辑相关,Excel 项目还面临着很多其他的挑战。大家都知道富文本编辑器很坑,但在 Excel 中,每个格子都是富文本编辑器。
富文本
富文本的编辑,一般有几种处理方式:
- 一个简单的 div 增加
contenteditable属性,用浏览器原生的execCommand执行 - div + 事件监听来维护一套编辑器状态(包括光标状态)
- textarea + 事件监听维护一套编辑器状态
对于contenteditable属性,要对选中的文本进行操作(如斜体、颜色),需要先判断光标的位置,用 Range 判断选中的文本在哪里,然后判断这段文本是不是已经被处理过,需要覆盖、去掉还是保留原效果,这里的坑比较多,也常常出现兼容性问题。
一般来说,像 Atom、VSCode 这些复杂的编辑器都是自己实现类似 contenteditable 功能的,使用 div+事件监听的方式。而 Ace editor、金山文档等则是使用隐藏的 textarea 接收输入,并渲染到 div 中来实现编辑效果。
复制粘贴
一般来说单个单元格或是多个单元格选中复制的时候,我们能拿到的是格子的原始数据,因此需要进行两步操作:将数据转换成富文本(拼接 table/tr/td 等元素),然后写入剪切板。
粘贴的过程,同样需要:从剪切板获取内容,再将这些内容转换成单元格数据,并提交操作数据。这里还可能涉及图片的上传、各种富文本的解析,每个单元格都可能由于设置的一些属性(包括合并单元格、行高列宽、筛选、函数等)而使得解析过程的复杂度直线上升。
复制粘贴相关功能模块复制粘贴根据使用场景可以分成两种:
- 内部复制粘贴。
- 外部复制粘贴。
内部复制粘贴指的是在自己产品内的复制粘贴,由于一个复制粘贴过程涉及的计算和解析都很多,内部复制粘贴可以考虑是否直接将单元格数据写入剪切板,粘贴的时候就可以直接获得数据,省去了将数据转换成富文本、将富文本解析成单元格数据等这些计算耗时较大、资源占用较多的步骤。
外部复制粘贴更多则是涉及到各种同类 Excel 编辑产品的兼容、系统剪切板内容格式的兼容,代码实现特别复杂。
表格渲染有多复杂
表格的绘制一般来说也有两种实现方案:
- DOM 绘制。
- canvas 绘制。
业界比较出名的 handsontable 开源库就是基于 DOM 实现绘制,但显而易见十万、百万单元格的 DOM 渲染会产生较大的性能问题。因此,如今很多 Web 版的电子表格实现都是基于 canvas + 叠加 DOM 来实现的,使用 canvas 实现同样需要考虑可视区域、滚动操作、画布层级关系,也有 canvas 自身面临的一些性能问题,包括 canvas 如何进行直出等。
表格渲染涉及合并单元格、选区、缩放、冻结、富文本与自动换行等各种各样的场景,我们来看看其中到底有多复杂。
自动换行
一般来说,一个单元格自动换行体现在数据存储上,只包括:单元格内容+换行属性。但这样一个数据需要渲染出来的时候,则面临着自动换行的一些计算:

我们需要找到该列的列宽,然后根据该单元格内容情况来进行渲染层的分行。如图,这样一串文本会根据分行逻辑的计算分成了三行。而自动换行之后,还可能涉及该单元格所在行的行高被撑起导致的调整,行高的调整可能还会影响该行其他单元格一些居中属性的渲染结果,需要重新计算。
因此,当我们对一列格子设置了自动换行,可能会导致大规模的重新计算和渲染,同样会涉及较大的性能消耗。
冻结区域
冻结功能可以将我们的表格分成四个区域,左右和上下划分了冻结和非冻结区域。冻结区域的复杂度主要在于边界的一些特殊情况处理,包括区域的选择、图片的切割等。我们来看一个图:
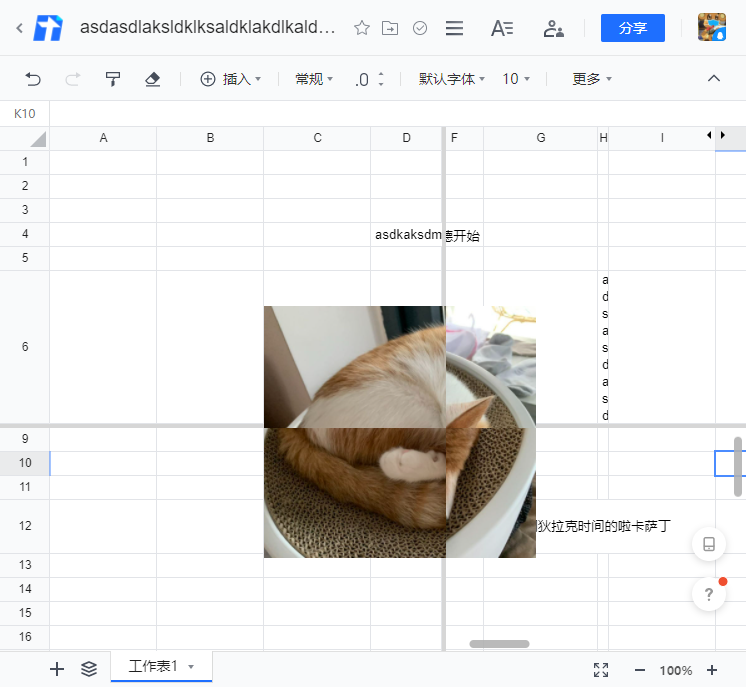
如图,对于一个图片来说,虽然它是直接放在整个表格上,但落到数据层中的时候,它其实只属于某一个格子。在冻结区域的编辑上,我们需要对它进行切分,但不管是哪个区域中选中它,我们依然需要展示它的原图:
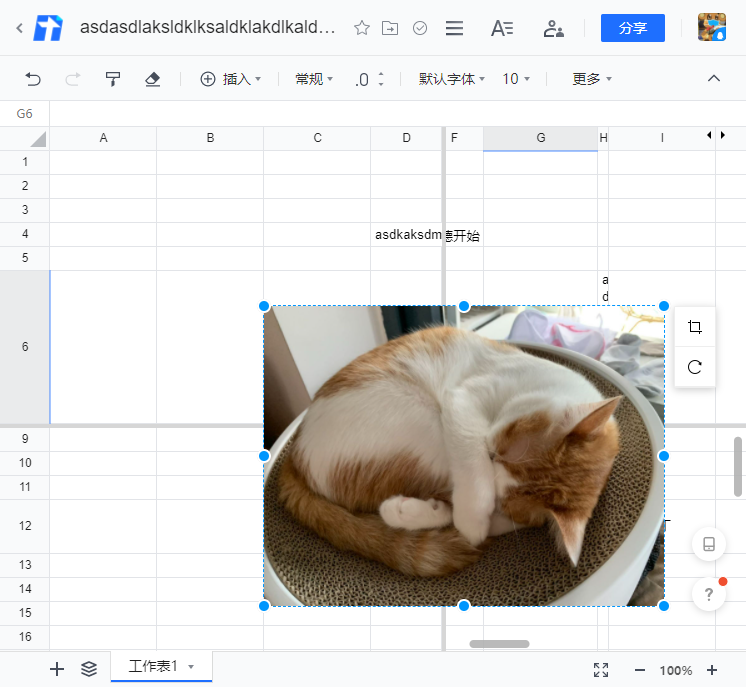
这意味着在 canvas 中,我们获取到鼠标点击的位置时,还需要计算出对应点击的格子是否属于图片覆盖范围内。
对齐与单元格溢出
一个单元格的水平对齐方式一般分为三种:左对齐、居中对齐、右对齐。当单元格没有设置自动换行,其内容又超出了该格子的宽度时,会出现覆盖到其他格子的情况:
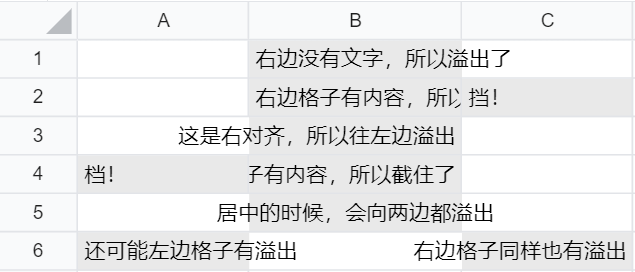
也就是说,我们在绘制某个格子的时候,同样需要计算附近的格子有没有溢出到当前格子的情况,如果有溢出则需要在这个格子里进行绘制。除此之外,当某列格子被隐藏的时候,溢出的逻辑可能还需要进行调整和更新。
以上列出的,都只是某一些比较细节的点,而表格的渲染还涉及单元格和行列的隐藏、拖拽、缩放、选区等各种逻辑,还有单元格边框的一些复杂计算。除此之外,由于 canvas 渲染是一屏的内容,涉及页面的滚动、协同数据的更新等会同样可能导致画布频繁更新绘制。
数据管理的难题
当每个格子都支持富文本内容,在十万、百万单元格的场景下,对落盘数据的存储、用户操作的数据变更也提出了不小的挑战。
原子操作
和数据库的事务相类似,对于电子表格来说,我们可以将用户的操作拆分成不可分割的原子操作。为什么要这么做呢?其实主要是方便进行 OT 算法的冲突处理,可针对每个不可拆分的原子操作进行特定逻辑的冲突计算和转换,最终落盘到存储中。
例如,我们插入一个子表这样一个操作,除了插入自身的操作,可能需要对其他子表进行移动操作。那么,对于一个子表来说,我们的操作可能会包括:
- 插入
- 重命名
- 移动
- 删除
- 更新内容
- …
只要拆分得足够仔细,对于子表的所有用户行为,都可以由这些操作来组合成最终的效果,这些不再可拆分的操作便是最终的原子操作。例如,复制粘贴一张子表,可以拆分为插入-重命名-更新内容;剪切一张子表,可以拆分为插入-更新内容-删除-移动其他子表。通过分析用户行为,我们可以提取出这些基本操作,来看个具体的例子:
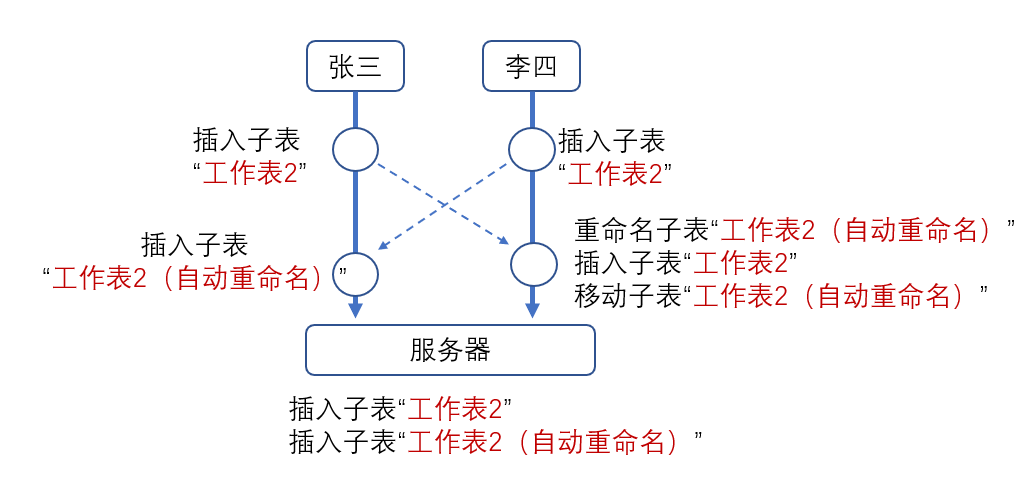
如图,对于服务端来说,最终就是新增了两个子表,一个是张三的“工作表 2”,另一个是李四的“工作表 2(自动重命名)”。
在实现上,一般使用 tranform 函数来处理并发操作,该函数接受已应用于同一文档状态(但在不同客户端上)的两个操作,并计算可以在第二个操作之后应用并保留第一个操作的新操作操作的预期更改。
在不同的 OT 系统中使用的 OT 函数的名称可能有所不同,但是可以将其分为两类:
- inclusion transformation/forward transformation:表示为
IT(opA, opB),opA以一种有效地包含opB的影响的方式,将操作转换为另一个操作opB'。 - exclusion transformation/backward transformation:表示为
ET(opA, opB),opA以一种有效排除opB影响的方式,将操作转换为另一操作opB''。
一些 OT 系统同时使用 IT 和 ET 功能,而某些仅使用 IT 功能。OT 功能设计的复杂性取决于多种因素:OT 系统是否支持一致性维护、是否支持 Undo/Redo、要满足哪些转换属性、是否使用 ET、OT 操作模型是否通用、每个操作中的数据是按字符(单个对象)还是按字符串(对象序列)、分层还是其他结构等。
除了客户端收到服务器的协同消息之后需要进行本地的冲突处理,服务器也可能存在先后接收到两个基于同一版本的消息之后进行冲突处理。在本地和服务器都有一套一致的冲突处理逻辑,才能保证算法的最终一致性。
版本回退/重做
对于大多数编辑器来说,Undo/Redo 是最基础的能力,文档编辑也不例外。前面我们提到实时协同有版本的概念,同时用户的每一个操作可能会被拆分成多个原子操作。
在这样的场景下,Undo/Redo 既涉及到落盘数据的恢复,还涉及到用户操作的还原时遇到冲突的一些处理。在多人协同的场景下,如果在编辑过程中接收到了其他人的一些操作数据,那么 Undo 的时候是否又会撤回别人的操作呢?
基于 OT 算法的 Undo 其实思路相对简单,通常是针对每个原子操作实现对应的invert()方法,进行该原子操作的逆运算,生成一个新的原子操作并应用。
前面我们介绍 transform 函数可以分为 IT 和 ET 两类,而 Undo 的实现有两种方式:
- Inv & IT: invert + inclusion transformation
- ET & IT: exclusion transformation + inclusion transformation
不管是哪种算法,OT 用于撤消的基本思想是根据操作之后执行的那些操作的效果,将操作的逆操作(待撤消的操作)转换为新形式,从而使转换后的逆操作可以实现正确的 Undo 影响。但如果用户在编辑的时候接收到了新的协同操作,当该用户在进行 Undo 的时候,通过逆运算生成的原子操作同样需要和这些新来的协同消息进行冲突处理,才能保证最终一致性。
数据
对于支持富文本的单元格来说,每个单元格除了自身的一些属性设置,包括数据格式验证、函数计算、宽高、边框、填充色等,还需要维护该单元格内富文本格式、关联图片的一些数据。这些数据在面临十万甚至百万单元格的时候,对数据传输和存储也带来了不小的挑战。
修订记录的版本和还原、如何优化内存、如何优化数据大小、如何高效利用数据、如何降低计算时空复杂度等都成为了数据层面临的一些难题。
END
以上列举的,只占整个Excel项目的一小部分,而除此之外还有Worker、菜单栏、各种各样的feature功能,像数据格式、函数、图片、图表、筛选、排序、智能拖拽、导入导出、区域权限、搜索替换,每一个功能都会因为项目的复杂性而面临各式各样的挑战。
除此以外,各个模块之间功能解耦、100W+的代码怎么进行组织和架构设计、代码加载流程如何优化、多人协作导致的问题、项目的维护性/可读性、性能优化等都是我们经常需要思考的问题。
结束语
参与这样的项目,最大的感受是不需要再抓破脑袋去想某个项目还可以做出哪些亮点,因为可以做的事情实在是太多了。对于很多业务来说,代码质量、维护性和可读性也常常不受重视。我们常常因为项目本身的局限性(相对简单)而无法找到自己可以深挖的点,因此最后都是只能通过自动化、配置化的方式去尽可能地提升效能,但可以做的其实也很局限,自身的成长也因此受限。
大家经常调侃说前端的天花板太低,又说自己面临35岁被淘汰。抛去个人兴趣、热情和自身瓶颈这些原因,很多时候也是因为条件不允许、业务场景较简单,因此没有场景可以发挥自己的能力。以前我也觉得下班之后学习也是可以的,但如果上班就做着自己喜欢的工作,岂不是一举两得?
最后,欢迎大家各式各样的讨论和交流~
PS:我们腾讯文档团队还在招人噢~~
感兴趣的可以联系我,QQ: 1780096742,也可以投递简历到 wangbeishan@163.com(邮件可能回复不及时)

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢