
大型前端项目要怎么跟踪和分析函数调用链
更新日期:
相信不少有大型项目维护经验的小伙伴,都曾经遇到代码量太多、函数调用链路太长、断点断到头都要断等等问题。最近也在研究解决这个问题,本文分享下整体的思路和解决方案。
方案设计
简单做一个函数耗时分析的功能还是比较简单的,写代码也是比较容易的一部分。但如果让一个功能真正发挥它的价值,前期方案的设计和分析也是很重要的。
现状
一般来说,对于大型项目或是新人加入,维护过程(熟悉代码、定位问题、性能优化等)比较痛的有以下问题:
- 函数执行情况黑盒
- 函数调用链不清晰
- 函数耗时不清楚
- 代码异常定位困难
- 用户行为难以复现
要是遇到代码稍微复杂点,事件比较多、函数调用也特别多的,即使使用断点也能看到眼花,蒸汽眼罩都得多买一些(真的贵啊)。生活本来就比较难了,身为技术人的我们得用技术去提升下自身的生活和工作体验呀。
回到上面说到的现状,函数执行黑盒这块相信大家都比较容易考虑到,而在日常的问题定位中,很多情况下我们需要查用户的问题,但是用户的反馈常常表达上会和我们理解的不一致。那如果能直接还原用户的操作,那岂不是棒棒哒?
目标
那既然现状有了,我们可以根据自己的需要,把目标确定下来。
个人觉得,即使是技术人员,前期的目标和现状分析也是很重要的。我们常常会遇到很多项目进行到一半发现和预期不一致、需要重新返工甚至只能放弃,往往是因为前期做的调研不充分,考虑到的情况还不够多。综上,设计的部分也需要好好去做,至于具体的方式,是手稿、文字、流程图、还是 PPT,可以根据个人喜好去选择。
那么,我先来拆分下自己想要的功能是什么样子的:
- 基础能力
- 单个函数执行情况:函数名、入参、出参、耗时
- 全局辅助信息:函数调用链、调用次数统计
- 便捷接入
- 不改动源码
- 易拓展
- 可重放功能
- 可保存到服务器
首先,基本功能必不可少,主要包括函数的一些执行情况,例如调用链、函数名、类名、入参出参,还有性能分析相关的,包括耗时、函数调用次数的统计等。这些在我们分析和定位问题的时候,能派上不少的用场。
其次,对于这部分功能代码,需要满足易用性,包括易接入、易拓展等。易接入主要考虑不需要改动源代码,这也是代码设计中比较基础的要求了。易拓展则预留给后续想要在现有功能基础上添加新功能的时候,会相对简便。
整体方案设计
方案设计也不算复杂,基本上就是结合目标,然后以自己最熟练的方向作为起点,一点点把完整的功能视图补全。最后,再回顾下前面的现状和目标,分析设计出来的方案是否有脱离实际需要(有时候我们的脑补能力很强大,容易飘离本意)。
说起函数,最简单的就是给每个想要检测的函数包裹一层,除了调用原有的功能以外,新增对函数的一些数据采集,包括上面说到的单个函数执行信息和全局的辅助信息等。
要怎么方便地使用这些信息呢?我们可以通过堆栈的方式存下来,然后对这些信息进行处理来获取调用链、耗时等。通常来说,可以暴露全局变量的接口,来快速打印输出这些信息。
我们来看看设计方案:
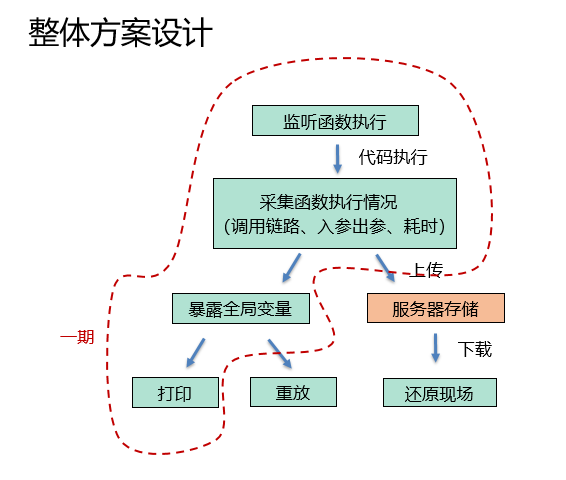
这里,将函数重放和上传服务器的优先级降低,先实现核心功能。工作内容的拆分、工作量的预估这些也都是方案设计中比较重要的部分,将大目标拆分成一个个小目标,这样对整体节奏、实现过程的把控会更有力。
方案细节设计
整体方案初步定了,我们需要考虑每个环节的细节方案。以一期的功能为主,流程包括以下:
1. 监听函数执行。
2. 采集函数执行情况:(调用链路、入参出参、耗时)。
3. 暴露全局变量或 API。
4. 使用全局变量或 API 打印调用链等。
由于这是一个非关键链路的功能,除了怎样的功能更方便使用以外,主要考虑这样的旁路功能不能影响主要功能的性能、不能因为一些异常导致正常功能无法使用。因此我们需要对每个流程进行一些分析和考虑:
- 监听函数执行
- 可通过依赖注入的方式,减少对源代码的入侵
- 代码实现多基于 Class,可考虑装饰器 Decorator 的方式
- 采集函数执行情况
- 需要注意性能和存储消耗,保证原有功能健壮性
- 考虑使用栈来存储
- 存储考虑链路长度限制、参数长度限制、链路数量上限
- 设置优先级,根据优先级选择性采集
- 旁路功能可考虑丢Worker执行
- 考虑通信对性能的消耗
我们能看到方案的一些细节如图: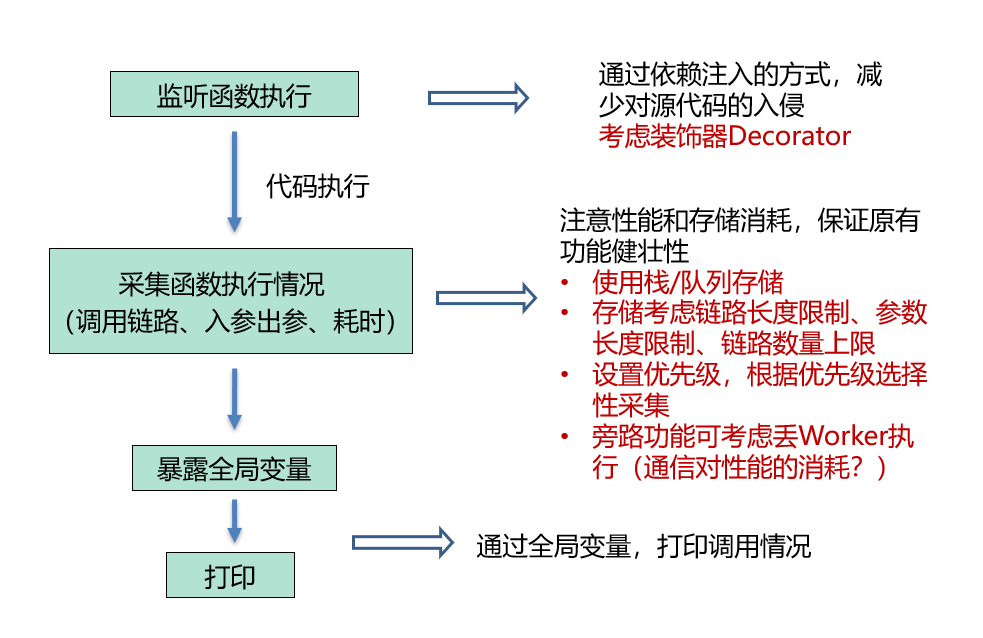
至此,大致的方案设计已经完成。
函数调用链的设计和实现
其实对于函数耗时统计的,网上也有一大堆的代码可以搜到,其中基于装饰器实现的也很多。由于我们项目中代码大多数都是基于 Class 设计的,因此装饰器这种不影响源代码的方式更加适合。
单次追踪对象
装饰器的实现其实不难,网上也有很多可以参考的。而我们装饰器里的具体逻辑是怎样的,依赖我们设计的单次追踪对象和调用栈是怎样的。因此,我们可以先设计一下单次追踪对象。
该对象要实现的功能包括:
- 特殊 ID 标记本追踪对象(
traceId)。创建该次对象的时候,自动生成该 ID。 - 可更新追踪对象的信息(
update方法)。 - 执行该追踪对象(
exec方法)。为重放功能做铺垫,如果我们存储了该函数以及函数入参,理想情况下可认为该函数可重放 - 打印该追踪对象相关信息(
print方法)。
来,直接看大致的代码设计:
1 | interface IFunctionTraceInfo { |
追踪堆栈
除了单次的追踪堆栈,我们还需要根据函数执行的顺序等维护完整的调用链信息,因此我们需要一个堆栈来维护完整的调用链。
那么,这个堆栈的功能也应该包括:
- 当前的层次(
level)。为调用链做铺垫,可认为函数开始执行的时候level++,函数结束的时候level--。- 当多个函数交错执行的时候(例如事件触发),该方式可能不准确
- 堆栈信息(
traceList)。 - 开始记录某次追踪(
start方法)。添加该次追踪之后将level++,便于记录当前追踪的层次。 - 结束记录某次追踪(
end方法)。level--。 - 获取某次追踪对象(
getTrace方法)。可用于单次追踪对象的信息获取和操作。 - 打印堆栈信息。结合当前层次,通过缩放打印对应的调用信息,可包括耗时等。
- 打印堆栈中函数的调用次数。以调用次数该维度打印堆栈中的追踪信息,可用于分析函数调用次数是否符合预期。
同样的,我们来看看代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49interface StashFunctionTrace {
traceLevel?: number;
trace: FunctionTrace;
}
class FunctionTraceStash {
level: number; // 当前层级,默认为0
traceList: StashFunctionTrace[]; // Trace数组
constructor() {
this.level = 0;
this.traceList = [];
}
// 开始本次 Trace
// 添加该 Trace 之后将 level + 1,便于记录当前 Trace 的层次
start(trace: FunctionTrace) {}
// 结束本次 Trace
end() {}
// 根据 traceId 获取某个 Trace 对象
getTrace(traceId: string): StashFunctionTrace | null {
return this.traceList.find((stashTrace) => stashTrace.trace.traceId === traceId) || null;
}
// 打印 Trace 堆栈信息
printTraceList(): string {
const traceStringList: string[] = [];
this.traceList.forEach((stashTrace) => {
let prefix = '';
if (stashTrace.traceLevel && stashTrace.traceLevel > 0) {
// 根据层次,前置 tab
prefix = new Array(stashTrace.traceLevel).join('\t');
}
traceStringList.push(prefix + stashTrace.trace.print());
});
return traceStringList.join('\n');
}
// 打印函数调用次数统计
printTraceCount(className?: string, functionName?: string) {}
// 重放该堆栈
replay() {}
// 清空该堆栈信息
clear() {}
}
装饰器逻辑
到这里,我们可以确定装饰器需要进行哪些操作:
- 生成追踪记录
new Trace(执行信息),包括入参、类名、方法名等。 TraceStash.add(Trace)添加层次。originFun()包裹原有函数、执行。Trace.update()更新一些信息,包括函数耗时、出参等。TraceStash.end()结束本次调用。
为了方便使用,我们可以设计基于Class的装饰器,以及基于Class.methods方法的装饰器,还可以基于单函数的装饰器。
我们还可以通过AST分析自动给代码中需要的部分添加上装饰器。至于装饰器具体实现,大家下来可以自己想一下。
结束语
很多人喜欢拿了任务就直接开撸,然后就会在写代码的过程中发现一个又一个问题。幸运的话,最终能做出想要的效果。而运气不好的话,可能得推倒重来了。
而在开始写代码之前,稍微进行一些分析、思考和调研,可以得到事半功倍的效果。

码生艰难,写文不易,给我家猪囤点猫粮了喵~
查看Github有更多内容噢:https://github.com/godbasin
更欢迎来被删的前端游乐场边撸猫边学前端噢
如果你想要关注日常生活中的我,欢迎关注“牧羊的猪”公众号噢