听说程序员里存在一个鄙视链,而前端则在鄙视链的最底端。这是因为以前大多数的前端工作内容都相对简单(或许现在也是如此),在大多数人的眼中,前端只需要写写 HTML 和 CSS,编写页面样式便完成了。
如今尽管前端的能力越来越强了,涉及到代码构建、编译等,但依然有十分丰富且成熟的工具可供使用,因此前端被认为是可替代性十分强的职位。在降本增效大时代,“前端已死”等说法也常常会被提出来。
这些说法很多时候是基于前端开发的工作较简单,但实际上并不是所有的开发工作都这么简单的,前端也会有涉及到算法与数据结构的时候。
今天我们来看看 R-tree 在前端中的应用。
# 树的数据结构
树在前端开发里其实并不应该很陌生,浏览器渲染页面过程中必不可缺,包括 HTML 代码解析完成后得到的 DOM 节点树和 CSS 规则树,布局过程便是通过 DOM 节点树和 CSS 规则树来构造渲染树(Render Tree)。
基于这样一个渲染过程,我们页面的代码也经常是树的结构进行布局。除此之外,热门前端框架中也少不了 AST 语法树,虚拟 DOM 抽象树等等。
# R-tree
我们来看一下 R 树是什么(来自维基百科) (opens new window):
R 树(R-tree)是用来做空间数据存储的树状数据结构,例如给地理位置,矩形和多边形这类多维数据建立索引。在现实生活中,R 树可以用来存储地图上的空间信息,例如餐馆地址,或者地图上用来构造街道,建筑,湖泊边缘和海岸线的多边形。然后可以用它来回答“查找距离我 2 千米以内的博物馆”,“检索距离我 2 千米以内的所有路段”(然后显示在导航系统中)或者“查找(直线距离)最近的加油站”这类问题。R 树还可以用来加速使用包括大圆距离在内的各种距离度量方式的最邻近搜索。
R 树的核心思想是聚合距离相近的节点,并在树结构的上一层将其表示为这些节点的最小外接矩形,这个最小外接矩形就成为上一层的一个节点。R 树的“R”代表“Rectangle(矩形)”。因为所有节点都在它们的最小外接矩形中,所以跟某个矩形不相交的查询就一定跟这个矩形中的所有节点都不相交。
一个经典的 R 树结构如下:
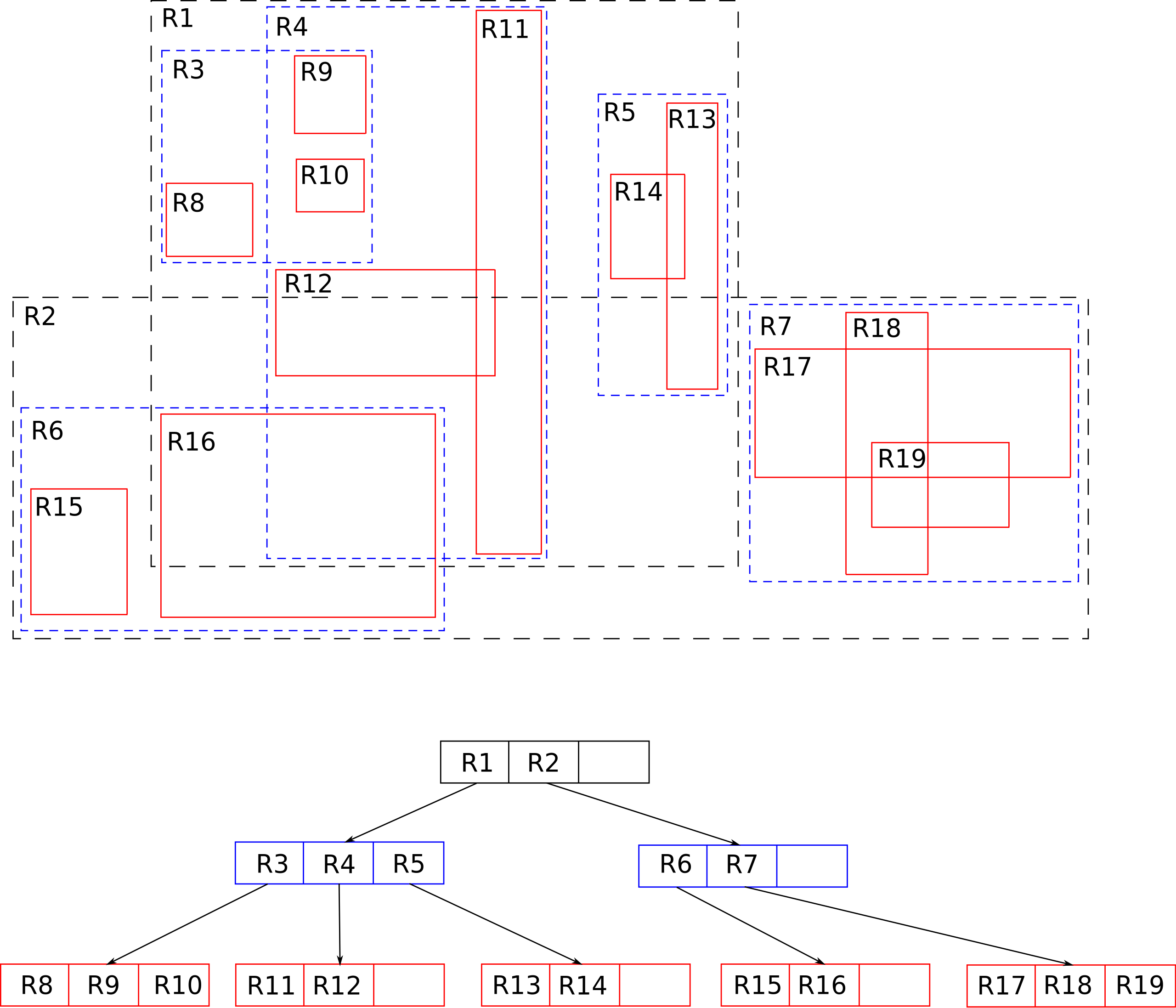
至于 R 树的算法原理以及复杂度这里就不多介绍了,书上网上都有许多可以供学习的内容参考,我们主要还是介绍算法的应用场景。
在与图形相关的应用中经常会使用到 R 树,除了上述提到的地图检索以外,图形编辑中也会使用到(检索图形是否发生了碰撞)。
除此之外,还有在表格场景下,天然适合使用 R 树来管理的数据,主要是范围数据,比如函数依赖的区域范围、条件格式的范围设置、区域权限的范围数据等等。
# Rbush
前端开发使用 R-tree 的场景大多数是 2D 下,包括上述提到的地图检索、图形碰撞检测、数据可视化、表格区域数据等等。
虽然我们经常在面试中会问到一些数据结构和算法,甚至有些时候还要求手写出来。但实际上在我们开发的时候,并不需要什么都自己实现一遍。学习算法的目的并不是要完全能自己实现,而是知道在什么场景下使用怎样的算法会更优,因此使用开源稳定的工具也是一种很好的方式。
RBush (opens new window) 是一个高性能 JavaScript 库,用于对点和矩形进行 2D 空间索引。它基于优化的 R 树数据结构,支持批量插入。其使用的算法包括:
- 单次插入:非递归 R 树插入,最小化 R* 树的重叠分割例程(分割在 JS 中非常有效,而其他 R* 树修改,如溢出时重新插入和最小化子树重叠搜索,速度太慢,不值得)
- 单一删除:使用深度优先树遍历和空时释放策略进行非递归 R 树删除(下溢节点中的条目不会被重新插入,而是将下溢节点保留在树中,只有当其为空时才被删除,这是查询与删除性能之间的良好折衷)
- 批量加载:OMT 算法(Overlap Minimizing Top-down Bulk Loading)结合 Floyd–Rivest 选择算法
- 批量插入:STLT 算法(小树-大树)
- 搜索:标准非递归 R 树搜索
我们也可以看到,整个 Rbush 的实现非常简单 (opens new window),甚至实现代码都没有 demo 和测试代码多。
使用方式很简单,我们来用个实际场景来使用看看。
# 表格区域数据
表格中使用到区域的地方十分多,前面提到了函数引用区域、条件格式区域、区域权限区域,除此之外还有区域样式、图表区域等等。这些区域因为不会覆盖,支持堆叠、交错,我们在管理的时候使用 R 树来维护,性能会更好。
基于 Rbush 实现,我们需要定义这个 Rbush 结点的数据。假设我们现有的表格区域数据为:
interface ICellRange {
startRowIndex: number; // 起始行位置
endRowIndex: number; // 结束行位置
startColumnIndex: number; // 起始列位置
endColumnIndex: number; // 结束列位置
}
那么每个区域都有对应要存储的数据(data),那么我们可以这么定义我们的 R 树:
import RBush from "rbush";
// 树节点的数据格式
export interface ITreeNode<T> {
range: ICellRange;
data?: T;
}
export class RTree<T> extends RBush<ITreeNode<T>> {
public toBBox(treeNode: ITreeNode<T>) {
const { range } = treeNode;
// 将单元格范围,转换为 Rbush 范围
return {
minX: range.startColumnIndex,
maxX: range.endColumnIndex,
minY: range.startRowIndex,
maxY: range.endRowIndex,
};
}
// 需要自行实现的比较
public compareMinX(treeNode1: ITreeNode<T>, treeNode2: ITreeNode<T>) {
return treeNode1.range.startColumnIndex - treeNode2.range.startColumnIndex;
}
public compareMinY(treeNode1: ITreeNode<T>, treeNode2: ITreeNode<T>) {
return treeNode1.range.startRowIndex - treeNode2.range.startRowIndex;
}
// 转换一下数据范围
public searchTreeNodes(cellRange: ICellRange): ITreeNode<T>[] {
return this.search({
minX: cellRange.startColumnIndex,
maxX: cellRange.endColumnIndex,
minY: cellRange.startRowIndex,
maxY: cellRange.endRowIndex,
});
}
}
那么,我们表格的许多数据结构都可以基于这个封装了一层的 RTree 来实现。举个区域权限的例子,我们在表格中设置了两个区域权限,显然堆叠部分会需要两个权限都满足才可以编辑:

这样一个查询权限的方法也很简单:
import { RTree } from "../r-tree";
// 区域权限数据
export interface IAuthRangeData {
cellRange: ICellRange;
rangeStatus: "unreadable" | "readonly" | "edit";
userIds?: string[];
}
export class AuthRangesTree {
private authRangeTree: RTree<IAuthRangeData> = new RTree(7);
// 检索某个用户是否有该区域权限
public hasRangesAuth(
cellRange: ICellRange,
userId: string
): IAuthRangeData[] {
const authRange = this.authRangeTree.searchTreeNodes(cellRange);
// 若没有设置区域权限,则默认有权限
if (!authRange.length) return true;
// 若有设置区域权限,则判断是否全满足
return !authRange.find((range) => !range.data.userIds.includes(userId));
}
}
这样,通过使用 R 树来存储数据的方式,我们可以极大地提升页面查询区域权限的性能。毕竟,如果我们只是单纯使用数据的方式去存储,那么每次查询都需要对整个数组遍历并进行碰撞检测,当表格单元格数量达到百万甚至千万时,这个性能问题可不是小事情了。
# 结束语
前面说过后面会详细介绍一些性能优化的具体例子,本文 R 树的使用便也是其中一个。当然,使用更优的数据结构和算法可以有不少的性能优化,而更多时候我们代码本身编写的问题也经常是导致性能问题的原因,定位并解决这些问题也是零碎但必须解决的事情。
如果有机会的话,后面看看攒一批代码习惯导致的性能问题,来分享给大家哇。
