最近在负责通用网络层的设计和开发,会记录该过程中的一些思考,本文主要介绍职责驱动设计,以及它在网络层设计中的一些思考。
之前有整理过《在线文档的网络层设计思考》一文,其中有较完整地介绍了网络层的一些职责,包括:
- 校验数据合法性
- 本地数据准确的提交给后台:包括有序递交和按序升版
- 协同数据正确处理后分发给数据层:包括本地未递交数据与服务端协同数据的冲突处理和协同数据的按序应用
在最初的想法中,我认为的网络层整体设计大概如下:
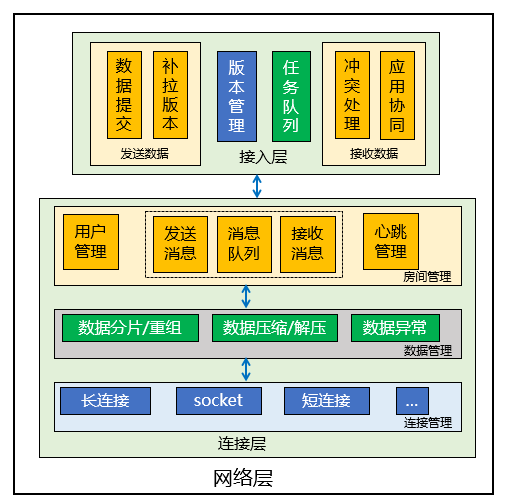
这是一个特别粗略的设计,其中有不少问题:
- 连接层的职责主要是与服务端的通信,因此房间管理、消息队列等逻辑不应该放在连接层中。
- 接入层的模块职责划分不清,各个功能职责耦合在一起。
- 网络层与业务的依赖关系不清晰,如果需要实际进行开发,则必须梳理清楚这些关系。
# 接入层设计
我们看到原本的接入层设计大概是这样的:
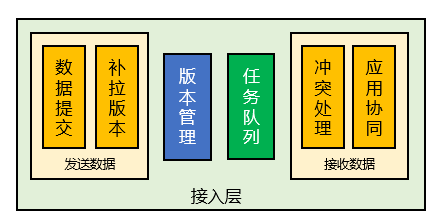
其中,发送数据的模块其实还包含着一个数据队列,而同时网络层的整体状态也看不到在哪里维护,导致这些问题主要是因为模块的职责划分不清晰。
# 职责驱动设计
在面向对象编程中,有一种设计模式叫职责驱动设计(Responsibility-Driven Design,简称 RDD),最典型的就是“客户端-服务端”模型。职责驱动设计于 1990 年构想,是从将对象视为[数据+算法]到将对象视为[角色+职责]的转变。
驱动设计的概念或许大家都很熟悉:
- 测试驱动开发(Test-driven Development,简称 TDD)讨论在编写生产代码之前先编写测试
- 数据驱动开发(Data-Driven Development)讨论在数据功能中定义处理策略
- 事件驱动开发(Event-Driven Programming)讨论在基于事件的程序中定义处理策略
- 领域驱动设计(Domain-Driven Design,简称 DDD)谈论通过使用通用语言来解决领域问题
其中,在大型复杂系统设计中流行的领域驱动设计,主要是从业务领域的角度来对系统进行领域划分和建模。相对的,职责驱动设计(RDD)则可用于从系统内部的角度来进行职责划分、模块拆分以及协作方式。
在基于职责的模型中,对象扮演特定角色,并在应用程序体系结构中占据公认的位置。整个应用程序可视作一个运行平稳的对象社区,每个对象都负责工作的特定部分。每个对象分配特定的职责,对象之间以明确定义的方式协作,通过这种方式构建应用程序的协作模型。
# GRASP
要给类和对象分配责任,可以参考 GRASP(General Responsibility Assignment Software Patterns)原则,其中使用到的模式有:控制器(controller)、创建者(creator)和信息专家(information expert);使用到的原理包括:间接性(indirection)、低耦合(low coupling)、高内聚(high cohesion)、多态(polymorphism)、防止变异(protected variations)和纯虚构(pure fabrication)。
这里面有很多都是大家开发过程中比较熟悉的概念,我来进行简单的介绍:
- 信息专家:在职责分配过程中,我们会将某个职责分配给软件系统中的某个对象类,它拥有实现这个职责所必须的信息。我们称这个对象类叫“信息专家”。
- 创建者:创建者帮助我们创建新对象,它决定了如何创建这些对象,比如使用工厂方法和抽象工厂。
- 控制器:控制器是一种将工作委派给应用程序适当部分的服务,主要用于将职责进行分配,比如常见的 MVC 架构模式中的控制器。
- 低耦合、高内聚:每个软件系统在其模块和类之间都有关系和依赖性,耦合是衡量软件组件如何相互依赖的一种方法。低耦合基于抽象,使我们的系统更具模块化,不相关的事物不应相互依赖;高内聚则意味着对象专注于单一职责。低耦合和高内聚是每个设计良好的系统的目标。
- 多态:用于表示具有不同行为的相关类,使用抽象而不是特定的具体实现。
- 防止变异:可理解为封装,将细节封装在内部。如果内部表示或行为发生了变化,保持其公共接口的不变。
- 纯虚构:为了保持良好的耦合和内聚,捏造业务上不存在的对象来承担职责。
其实,RDD 本身的设计具备更多的角色,包括服务提供商、接口、信息持有人、控制器、协调员、结构师;也具备更多的职责分配原则和模式,通常包括:
- 将信息保存在一个地方,比如“单点原则”
- 保持较小的职责,比如“得墨忒耳定律(Law of Demeter)-最少的知识原理”
- 包装相关的操作,比如“Whole Value Object”
- 仅使用需要的内容,比如“接口隔离原则”
- 一致的职责,比如“单一职责原则”
- 等等
我们来看看,在网络层中是否可以使用职责驱动的方式来得到更好的设计。
# 接入层职责划分
上一篇文章中我也有介绍,在线文档中从后台获取的数据到前端的展示,大概可以这么进行分层:
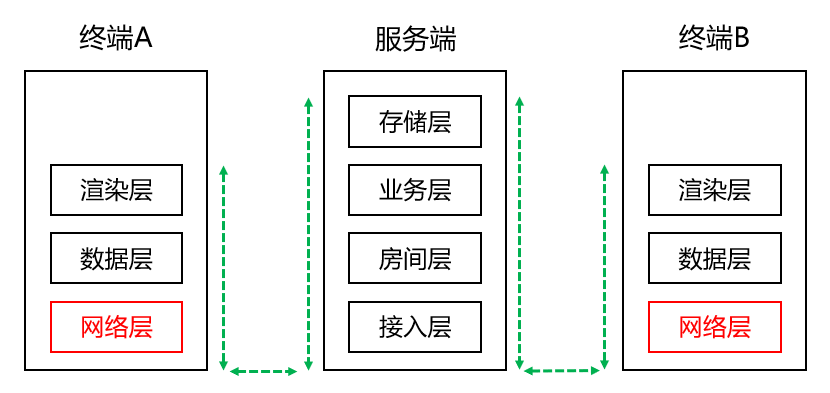
其实当我们在给系统分层、分模块的时候,很多时候都会根据职责进行划分,比如在这里我们划分成了:
- 网络层:负责与服务端的数据提交、接收等处理
- 数据层:负责数据的处理
- 渲染层:负责界面的渲染
这是很粗略的划分,实际上关于网络层的数据如何更新到数据层,数据层的变更又如何通知给渲染层,这些模块之间是有很多依赖关系的。如果我们只做最简单的划分,而不把职责、协作方式等都定义清楚,很可能到后期就会变成 A 模块里直接调用 B 模块,B 模块里也直接调用 A、C、D 模块,或者是全局事件满天飞的情况。
关于模块与模块间的耦合问题,可以后面有空再讨论,这里我们先回到网络层的设计中。
# 按职责拆分对象
上面说的有点多,我们再来回顾下之前的接入层设计:
可以看到,发送数据的模块中,夹杂着补拉版本的工作,实际上里面还需要维护一个用于按需提交的数据队列;接受数据的模块中,也同样存在着与业务逻辑严重耦合的冲突处理和应用协同等工作。在这样的设计中,各个对象之间的职责并不清晰,也存在相互之间的耦合甚至大鱼吃小鱼的情况。
根据 RDD,我们先来根据职责划分出可选的对象:
- 提交数据队列管理器:负责业务侧提交数据的管理
- 网络状态管理器:负责整个网络层的网络状态管理
- 版本管理器:负责网络层的版本管理/按序升版
- 发送数据管理器:负责接收来自业务侧的数据
- 接受数据管理器:负责接收来自连接层(服务端)的数据
按照职责拆分后,我们的网络层模块就很清晰了:
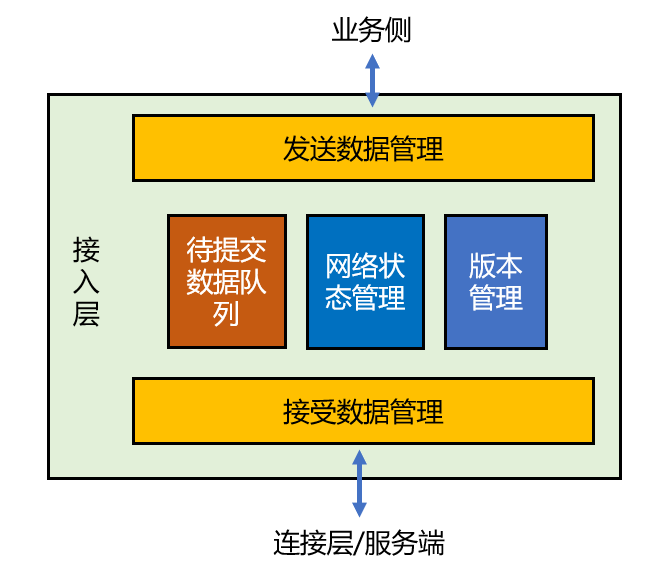
除了这些,还有提交数据队列中的数据、来自连接层(服务端)的数据等,也都可以作为候选对象:
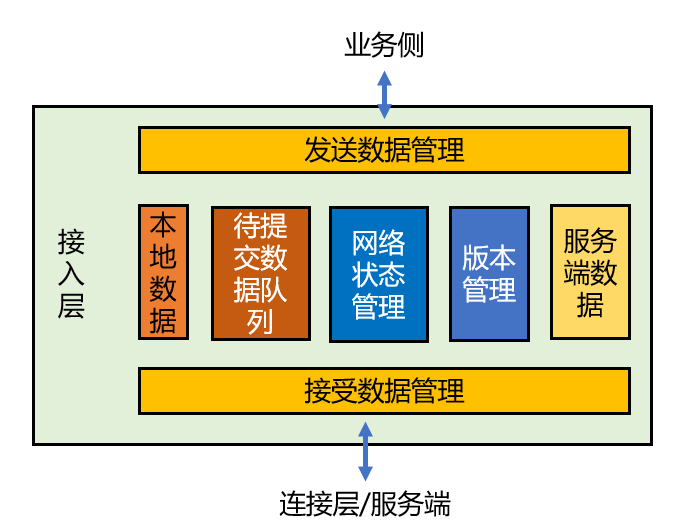
如果按照 GRASP 设计原则,这些都应该是信息专家(information expert),负责具体的某个职责。如果你仔细观察,会发现对比最初的设计,任务队列被丢掉了,因为它没有恨明确的职责划分。但是它真的不需要存在吗?我们继续来看看。
# 职责对象间的边界
前面也说过,如果我们只对系统进行职责划分,而不定义清楚对象之间的边界、协作方式,那么实际上我们并没有真正意义上地完成系统设计这件事。
在这里,我们根据职责划分简单地画出了各个对象间的依赖关系:
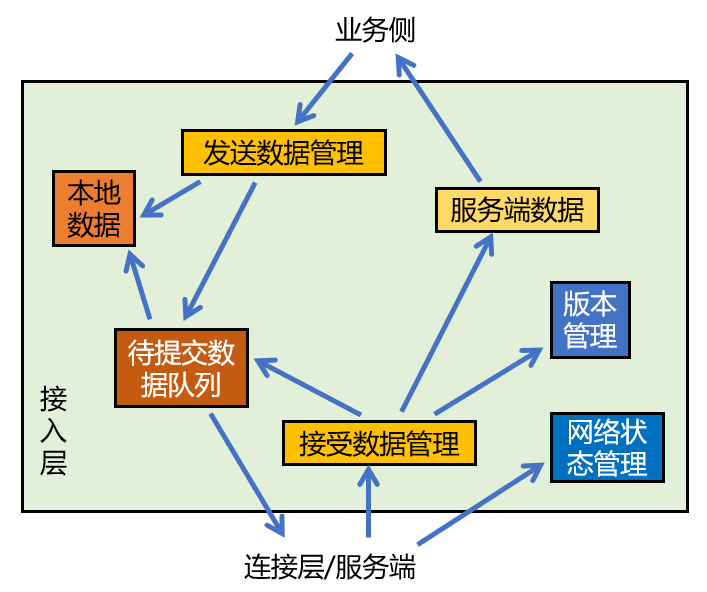
其实各个对象间的依赖关系远比这复杂,因此我们无法很清晰地解耦出各个对象间的依赖关系。此外,不管是业务侧还是连接层(服务端),都跟内部的具体某个对象有直接的依赖关系,这意味着外部模块依赖了内部的具体实现,不符合封装的设计,违反了接口隔离原则和防止变异(protected variations)原则。
为了解决这些情况,我们可以拆分出控制器来进行职责分配,以及使用纯虚构(pure fabrication)来让这些信息专家保持保持良好的耦合和内聚。
# 拆分出控制器
其实在上述的职责对象划分中,有两个管理器的职责并没有很明确:发送数据管理器和接受数据管理器。实际上,它们扮演的角色应该更倾向于控制器:
- 发送数据控制器:负责接收来自业务侧的数据,并提交到连接层(服务端)
- 接受数据控制器:负责接收来自连接层(服务端)的数据,并最终应用到业务侧
为了达到真正的控制器职责,发送数据控制器不仅需要将数据提交到连接层(服务端),也需要关注最终提交成功还是失败;接受数据控制器不仅需要接收来自连接层(服务端)的数据,还需要根据数据的具体内容,确保将数据正确地传递给业务侧。
因此,与业务侧和连接层(服务端)的依赖关系,都转接到发送数据控制器和接受数据控制器中:

但其实这样也依然存在外层对象依赖具体的实现的情况,我们可以添加个总控制器,来专门对接业务侧和连接层(服务端):
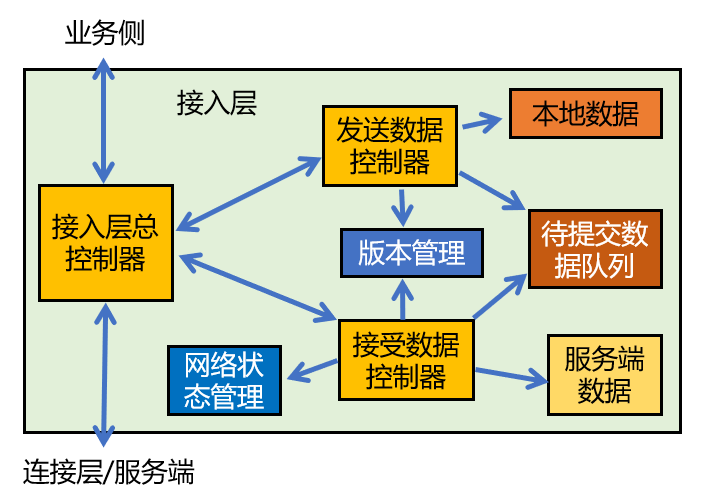
来自业务侧的提交数据,总控制器会交给发送数据控制器进行处理,包括添加到待提交数据队列、提交成功/失败的处理等;来自服务端的消息,总控制器则会交给接受数据控制器进行处理,包括版本相关的数据进行冲突处理、更新版本等等,最终也会通过总控制器同步给业务侧。
我们可以看到,通过控制器的加入,各个职责对象(信息专家)之间不再存在直接的依赖关系,相互之间的联系都是通过控制器来进行管理的,这样它们就可以保持单一的职责关系,也可以专注于与控制器的协作方式。
# 使用纯虚构
前面说过,纯虚构模式是为了保持良好的耦合和内聚,捏造业务上不存在的对象来承担职责。其实在上面我们添加了总控制器,也有用到了纯虚构。
那么现在还存在什么问题呢?在这里不管是本地数据提交完毕,还是服务端新数据的推送,发送数据控制器和接受数据控制器都会对版本管理进行更新。但实际上版本需要按序升版,因此当双方同时进行操作时,可能会导致版本错乱的问题,也可能造成版本丢失。
为了解决这个问题,我们可以构造一个版本管理的任务队列,所有和版本相关的更新都放到队列里进行处理:

任务队列每次只运行一个任务,任务在更新版本的时候确保了在原版本上按序升版。这样,不管是发送数据成功后的版本更新,还是接受到新的数据需要进行版本更新,都可以通过生成相关任务并添加到任务队列的方式,来进行版本升级。至于不同类型的任务,我们可以使用多态的方式来进行抽象和设计。
这样,每个对象的职责我们已经可确认了:
- 待提交数据队列管理器:负责维护业务侧提交的数据
- 网络状态管理器:负责维护整个网络层的网络状态
- 版本管理器:负责网络层的版本维护
- 任务队列管理器:负责按序升版相关的任务管理和执行
- 发送数据控制器:负责处理来自业务侧的数据,并保证数据顺序递交、按序升版
- 接受数据控制器:负责处理来自连接层(服务端)的数据,并保证数据完成冲突处理和应用
- 总控制器:负责接收来自业务侧和连接层(服务端)的数据,并分发给发送数据控制器和接受数据控制器
到这里,我们会发现对比初版设计,新版设计刚开始丢掉的任务队列也重新回来了,各个职责对象间的依赖关系也清晰了很多。而在实际开发和系统设计中,我们可以使用 UML 图来详细地画出每个对象的具体职责、对象之间的协作方式,这样在写代码之前就把很多问题思考清楚,也避免了开发过程中来回修改代码、职责越改越模糊等问题。
# 参考文章
- A Brief Tour of Responsibility-Driven DesignCompressed (opens new window)
- Responsibility Driven Design (opens new window)
- What are General Responsibility Assignment Software Patterns? (opens new window)
- 架构必修:领域边界划分方法 -- 职责驱动设计 (RDD) (opens new window)
# 总结
在本文中,我主要围绕着职责驱动设计的方式来进行接入层的设计思考,也更多关注于接入层内部各个职责对象的划分和依赖关系梳理。
但在实际开发中,我们还需要考虑更多各个对象之间的协作方式,它们之间的依赖要怎么进行合理地解耦,具体到写代码里面又会是怎样的表现,这些看看后面要不要继续讲~
