整理了下前端监控的一些项目经验,结合自己的想法输出了这篇文章,跟大家分享下。
# 前端监控体系搭建
通常前端建立搭建监控体系,主要是为了解决两个问题:如何及时发现问题、如何快速定位并解决问题。
一般来说,结合开发和产品的角度来看,前端监控体系需要做的事情包括:
- 页面的整体访问情况,包括常见的 PV、UV、用户行为上报。
- 页面的性能情况,包括加载耗时、接口耗时统计。
- 灰度发布与有效的监控能力,方便及时发现问题。
- 用户反馈问题,需要足够的日志定位问题。
这些问题可以从两个角度来解决:数据收集、数据上报。
# 数据收集
要进行有效地监控,首先我们需要将监控数据进行上报。传统的页面开发过程中,系统的质量通常从三方面来评估,针对页面的监控和数据采集也分别从这些方面来进行:
- 页面访问速度
- 页面稳定性/异常
- 外部服务调用情况
# 异常收集
首先,我们需要收集项目运行过程中的一些错误,因为一般来说脚本执行异常很可能会直接导致功能不可用。当 HTML 文档执行异常时,我们可以通过window.onerror、document.addEventlistener(error)、XMLHttpRequest status等方法拦截错误异常。例如,通过监听window.onerror事件,我们可以获取项目中的错误和分析堆栈,将错误信息自动上报到后台服务中。
常见的前端异常包括:
- 逻辑错误:开发实现功能的时候,逻辑梳理不符合预期
- 业务逻辑判断条件错误
- 事件绑定顺序错误
- 调用栈时序错误
- 错误的操作 js 对象
- 代码健壮性:代码边界情况考虑不周,异常逻辑执行出错
- 将 null 视作对象读取 property
- 将 undefined 视作数组进行遍历
- 将字符串形式的数字直接用于加运算
- 函数参数未传
- 网络错误:用户网络情况异常、后台服务异常等错误
- 服务端未返回数据但仍 200,前端按正常进行数据遍历
- 提交数据时网络中断
- 服务端 500 错误时前端未做任何错误处理
- 系统错误:代码运行环境兼容性问题、内存不够用等问题导致出错
- 页面内容异常:缺少内容、绑定事件异常、样式异常
# 生命周期数据
生命周期包括页面加载的关键时间点,常常包括页面打开、更新、关闭等耗时数据。
一般来说,我们可以通过 PerformanceTiming 属性获取到一些生命周期相关的数据,包括:
PerformanceTiming.navigationStart:当前浏览器窗口的前一个网页关闭,发生 unload 事件时的时间戳PerformanceTiming.domLoading:返回当前网页 DOM 结构开始解析时(即Document.readyState属性变为“loading”、相应的readystatechange事件触发时)的时间戳PerformanceTiming.domInteractive:返回当前网页 DOM 结构结束解析、开始加载内嵌资源时(即Document.readyState属性变为“interactive”、相应的readystatechange事件触发时)的时间戳PerformanceTiming.domComplete:返回当前文档解析完成(即Document.readyState变为"complete"且相对应的readystatechange)被触发时的时间戳PerformanceTiming.loadEventStart:返回该文档下,load 事件被发送时的时间戳PerformanceTiming.loadEventEnd:返回当 load 事件结束,即加载事件完成时的时间戳
除此之外,当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded事件被触发,而无需等待样式表、图像和子框架的完全加载。由于前端框架的出现,很多时候页面的渲染交给框架来控制,因此DOMContentLoaded事件已经失去了原本的作用,很多时候我们会在框架本身提供的生命周期函数中进行数据的收集。
我们还可以使用MutationObserver接口,该提供了监听页面 DOM 树变化的能力,结合performance获取到具体的时间:
// 注册监听函数
const observer = new MutationObserver((mutations) => {
console.log(`时间:${performance.now()},DOM树发生了变化!有以下变化类型:`);
for (let i = 0; i < mutations.length; i++) {
console.log(mutations[0].type);
}
});
// 开始监听document的节点变化
observer.observe(document, {
childList: true,
subtree: true,
});
# HTTP 测速数据
请求相关的数据,我们同样可以通过 PerformanceTiming 属性获取:
PerformanceTiming.redirectStart:返回第一个 HTTP 跳转开始时的时间戳PerformanceTiming.redirectEnd:返回最后一个 HTTP 跳转结束时(即跳转回应的最后一个字节接受完成时)的时间戳PerformanceTiming.fetchStart:返回浏览器准备使用 HTTP 请求读取文档时的时间戳,该事件在网页查询本地缓存之前发生PerformanceTiming.domainLookupStart/PerformanceTiming.domainLookupEnd:返回域名查询开始/结束时的时间戳PerformanceTiming.connectStart:返回 HTTP 请求开始向服务器发送时的时间戳PerformanceTiming.connectEnd:返回浏览器与服务器之间的连接建立时的时间戳,连接建立指的是所有握手和认证过程全部结束PerformanceTiming.secureConnectionStart:返回浏览器与服务器开始安全链接的握手时的时间戳PerformanceTiming.requestStart:返回浏览器向服务器发出 HTTP 请求时(或开始读取本地缓存时)的时间戳PerformanceTiming.responseStart:返回浏览器从服务器收到(或从本地缓存读取)第一个字节时的时间戳PerformanceTiming.responseEnd:返回浏览器从服务器收到(或从本地缓存读取)最后一个字节时(如果在此之前 HTTP 连接已经关闭,则返回关闭时)的时间戳
通过这些数据,我们可以观察后端服务是否稳定、是否还有优化空间。
# 用户行为数据
除了常见的前端页面加载、请求耗时数据,我们还可以关注用户的一些行为数据,包括页面浏览量或点击量、用户在每一个页面的停留时间、用户通过什么入口来访问该页面、用户在相应的页面中触发的行为。用户行为数据可以通过一些 DOM 元素的操作事件来获取。
这些数据通常用来统计分析用户行为,来针对性调整页面功能、更好地发挥页面的作用。同时,我们还可以通过一些用户交互数据,来观测系统功能是否正常。
# 用户日志
系统出现异常的时候,通常使用日志进行定位。日志的存储通常包括两种方案:
- 上报到服务器。由于日志内容很多,如果全量上报到服务器会导致存储成本过大,同时频繁的上报也会增加接口的维护成本。除此之外,由于网络原因等还可能导致部分或全部的日志丢失等问题。
- 本地存储。该方案需要引导用户手动操作提交本地日志,才可以定位到具体异常出现的位置。如果无法联系到用户,则可能由于异常无法重现而无法修复。
日志通常用户定位用户问题的时候使用,但我们常常需要提前在代码中打印日志。否则,当我们需要定位问题的时候,才发现自己并没有输出相关的日志,有些问题由于复现困难,再补上日志发布后也未必能复现,这样就会比较被动。
可以通过全局挟持关键模块和函数等方式来进行日志的自动打印,举个例子:
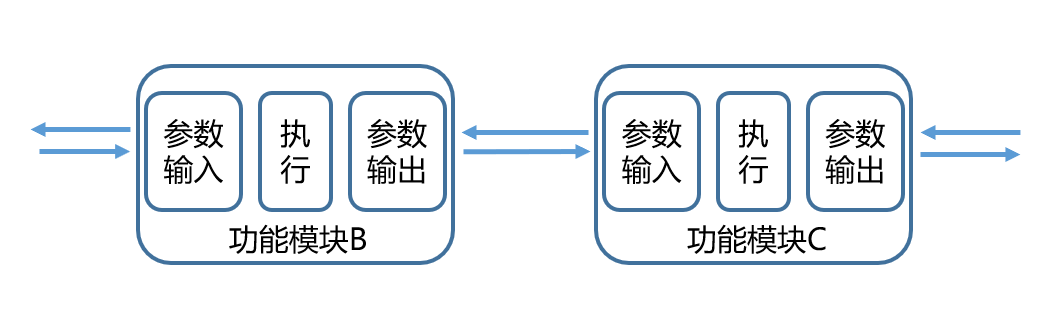
在每个功能模块运行时,通过使用约定的格式来打印输入参数、执行信息、输出参数,则可以通过解析日志的方式,梳理本次操作的完整调用关系、功能模块执行信息:

# 埋点方案
前端常见的埋点方案包括三种:
| - | 代码埋点 | 可视化埋点 | 无痕埋点 |
|---|---|---|---|
| 使用方式 | 手动编码 | 可视化圈选 | 嵌入 SDK |
| 自定义数据 | 可自定义 | 较难自定义 | 难以自定义 |
| 业界成熟产品 | 友盟、百度统计等第三方数据统计服务商 | Mixpanel | GrowingIO |
| 更新代价 | 需要版本更新 | 需要下发配置 | 不需要 |
| 使用成本 | 高 | 中 | 低 |
无痕埋点一般是通过上述数据采集中使用的一些 API 来进行数据的采集,但由于无痕埋点的自定义能力很弱,通常我们可以配合代码埋点的方式进行。
# 标准化埋点数据
不管是哪种埋点方式,我们都需要对它们进行标准化处理。一般来说,通过和后台约定好具体的参数,然后前端在埋点采集的时候,自动转换成接口需要的一些数据格式进行本地存储。
通过这些行为信息,可以实时计算出每个用户在时间轴上的操作顺序,以及每个步骤的操作时间、操作内容等,通过可视化系统直观地展示用户的链路情况,包括系统的入口来源、打开或关闭的页面、每个功能点的点击和操作时间、功能异常的情况等。
使用标准化的方式获取用户点击流以及页面使用情况,将页面和每个功能的操作行为上报到服务器,实时对操作时间、操作名称等信息来分析得到用户的操作链路、每个页面和功能操作步骤间的耗时和转化率,并进行有效监控。通过该方式,可以高效直观地观察产品的使用情况、分析用户的行为习惯,然后确定产品方向、完善产品功能。
# 数据上报
数据采集完成后,我们需要将这些数据上报到后台服务:

如图,当页面打开、更新、关闭等生命周期、用户在页面中的操作行为、系统异常等触发时,系统底层通过埋点监听这些事件,获取相关数据数据并进行标准化处理后,进行本地收集然后上报到实时数据分析系统。
相关的数据信息包括时间、名称、会话标记、版本号等信息,通过这些数据,可以实时计算出每个埋点的使用数量、埋点间的执行时间、埋点间的转换率等,通过可视化系统直观地展示完整的页面使用情况,包括每个页面打开、更新、关闭情况、每个功能点的点击和加载情况、功能异常的情况等。
# 上报方式
一般来说,我们埋点的数据、运行的日志都需要通过上报发送到后台服务再进行转换、存储和监控。
# 批量上报
对于前端来说,过于频繁的请求可能会影响到用户其他正常请求的体验,因此通常我们需要将收集到的数据存储在本地。当收集到一定数量之后再打包一次性上报,或者按照一定的频率(时间间隔)打包上传,打包上传将多次数据合并为一次,可以减轻服务器的压力。
# 关键生命周期上报
由于用户可能在使用过程中遇到异常,或者在使用过程中退出,因此我们还需要在异常触发的时候、用户退出程序前进行上传,以避免问题没能及时发现和定位。
# 用户主动提交
一些异常和使用体验问题,我们会给用户提供主动上传的选项。当用户经过引导后进行上传的时候,我们则可以将本地的数据和日志一并进行提交。
# 数据监控
数据上报完成后,我们需要搭建管理端对这些数据进行有效的监控,主要包括三部分的数据:
- 性能监控
- 网页加载性能
- 网络请求性能
- 异常监控
- JS Error
- 数据监控
- 页面 PV/UV
- 页面来源
日常监控中,我们可以通过对这些监控数据配置告警阈值等方式,结合邮件、机器人等方式推送到相关的人员,来及时发现并解决问题。
# 发布过程监控
多人协作的项目,由于每次发版都会把好几个小伙伴开发的功能一起合并发布,人工保证功能的正确是很低效的,人工测试也不一定能覆盖到很完整的功能、自动化测试也常常因为性价比等问题无法做得很完善。所以除了自动化测试、改动相关的功能自测之外,我们上报过程会带上每次的版本号,同时可以根据版本来观察新版本的曲线情况,在灰度过程也需要小心注意观察:
- 小程序错误告警是否有新增错误,可通过错误内容找到报错位置修复
- 全版本监控观察:整体的功能点覆盖曲线是否正常,是否有异常涨跌
- 分版本监控观察:功能是否覆盖完整、灰度占比是否正常、新旧版本的转化率是否一致
在灰度发布过程中,我们就能通过上报数据功能曲线是否正常、异常是否在预期范围、曲线突变跟灰度时间点是否吻合等,来确认是否有异常、哪里可能有异常。当出现数据异常的时候,可配合相应的告警渠道来及时通知相应的负责人,及时修复功能异常。

# 结束语
很多时候,前端项目中都会进行一些异常、耗时测速等监控,也会进行一些用户行为的数据上报。其实我们还可以思考将这些过程更加自动化地实现,同时数据在上报之后还可以进行筛选、统计、转换,计算出产品各种维度的使用情况,甚至还可以做全链路监控、或是给到一些实用的产品方向引导。
